Today marks 2 months since I was laid off from my job at DataRobot. It was part of a 25% reduction that was made in anticipation of the business slump from the COVID-19 pandemic, and having just been there for 6 months, I was one of the ones let go.
I have spent the last two months like most of you largely confined to my home, with only an occasional trip to the grocery store. Since I was home with all this newfound free time on my hands, I decided to work on a lot of projects that I’ve had to put off. Now that those are largely complete, I need to find a new outlet to occupy my time. So today I’m going to start on a program of writing every day; you’re reading the first entry.
Not to brag, but I’ve always been pretty good writer. The biggest problem that I have is perfectionism: I want to edit/rewrite until it can’t be tweaked any more. As an example, I was stuck for 10 minutes just coming up with a title for this post! I mentioned this tendency in the very first post of this blog: I was about to travel to Australia, and wanted to have a way to record my impressions. I had hardly ever traveled outside the US, so this was a really big deal for me.
I kept it up for a short while, but soon fell back into my old ways: starting a post, and then abandoning it because it didn’t feel good enough. When I joined IBM in 2014 as an OpenStack developer, part of my role was to be outspoken, and writing blog posts was one way to do that. So for a while I was posting fairly regularly. This time, though, it was the blowback from those posts that caused me to lose interest in writing. You see, the OpenStack developer hierarchy is designed to discourage change and alternate approaches, both of which were the frequent topics of my posts. It discouraged me because I was publicly criticized by many of the “core” developers, who seemed to take my ideas as threats to the way they were doing things. It was even more discouraging that I received at least as much private thanks and praise from others, all of whom were not comfortable expressing support publicly, less they lose political capital with the core developers. I have a post I started and never finished on this toxic atmosphere; maybe one of these days I’ll finish it as part of this new effort.
So I’m now going to reiterate my initial pledge: I will limit myself to a one edit rule: after the post is written, I’ll go over it once for typos, etc., and then publish it. I’m also setting a minimum of 30 minutes per day to write, and to publish it no matter how good I feel it is. There will be no set topic; one day it may be my thoughts on photographic composition, the next may be a tirade about the latest Trump atrocity. But I do hope that what I write is as interesting for you to read as it is for me to go through the process of writing.
It’s been a great run, but my days in the OpenStack world are coming to an end. As some of you know already, I have accepted an offer to work for DataRobot. I only know bits and pieces of what I will be working on there, but one thing’s for sure: it won’t be on OpenStack. And that’s OK with me, as I’ve been working on OpenStack in one form or another for 10 years now.
Wait a moment, you say – OpenStack is only 9 years old! Well, before the OpenStack project was started, I worked on Swift briefly when it was an internal, proprietary project at Rackspace. After that I switched to the Cloud Servers team, which was the team that started Nova with NASA. So yeah, it’s been a full decade. That’s a loooonnnnggg time to be on any development project!
So the feelings of burnout combined with the shift away from OpenStack within IBM made moving to DataRobot a very attractive option. And after having done several video interviews with the people there and getting their impression of life at DataRobot, I’m that much more excited to be joining that team. I’m sure that for the first few months it will be like drinking from the proverbial fire hose, and that’s perfectly fine by me. It’s been much too long since I’ve pushed the reset button for my career.
Over these past 10 years I have made many professional contacts, some of whom I consider true friends. I will miss the OpenStack community, and I hope to run into many of you at future tech events – PyCon, anyone?
OK, so the title of this is a bit clickbait-y, but let me explain. By some measures, OpenStack is a tremendous success, being used to power several public clouds and many well-known businesses. But it has failed to become a powerful player in the cloud space, and I believe the reason is not technical in nature, but a lack of leadership.
OpenStack began as a collaboration between Rackspace, a commercial, for-profit business, and a consulting group working for NASA. While there were several companies involved in the beginning, Rackspace dominated by sheer numbers. This dominance was a concern to many companies – why should they contribute their time and resources to a project that might only benefit Rackspace? This fear was not entirely unfounded, as the OpenStack API was initially created to match Rackspace’s legacy cloud API, and much of the early naming of things matched Rackspace’s terminology – I mean, who ever thought of referring to virtual machines as “servers”? But that matched the “Cloud Servers” branding that Rackspace used for its cloud offering, and that name, as well as the use of “flavor” for instance sizing, persist today. The early governance was democratic, but when one company has many more votes than the others…
The executives at Rackspace were aware of this concern, and quickly created the OpenStack Foundation, which would be an independent entity that would own the intellectual property, helping to guarantee that one commercial company would not control the destiny of OpenStack. More subtly, though, it also engendered a deep distrust of any sort of top-down control over the direction of the software development. Each project within OpenStack was free to pretty much do things however they wanted, as long as they remained within the bounds of the Four Opens: Open Source, Open Design, Open Development, and Open Community.
That sound pretty good, right? I mean, who needs someone imposing their opinions on you?
Well, it turns out that OpenStack needed that. For those who don’t know the term “BDFL“, it is an acronym for “Benevolent Dictator For Life”. It means that the software created under a BDFL is opinionated, but it is also consistently opinionated. A benevolent dictator listens to the various voices asking for features, or designing an API, and makes a decision based on the overall good of the project, and not on things like favoring corporate interests for big contributors, or strong personalities that otherwise dominate design discussions. Can you imagine what AWS would be like if each group within could just decide how they wanted to do things? The imposition of the design from above assures AWS that each of its projects can work easily with others.
The closest thing to that in OpenStack is the Technical Committee (TC), which “is an elected group that represents the contributors to the open source project, and has oversight on all technical matters”. Despite the typical meaning of “oversight”, the TC is essentially a suggestion body, and has no real enforcement power. They can spend months agonizing over the wording of mission statements and community goals, but shy away from anything that might appear to be a directive that others must do. I don’t think the word “must” is in their vocabulary.
They also bend over backwards to avoid potentially offending anyone. Here is one example from my interactions with them: one of the things the TC does is “tag” projects, so that newcomers to OpenStack can get a better idea how mature a particular project is, or how stable, etc. One of the proposed tags was to warn potential users that a project was primarily being developed by a single company; the concern is that all it would take is one manager at that company to decide to re-assign their employees, and the project would be dead. This is a very valid concern for open source projects, and it was proposed that a tag named “team:diverse-affiliation-danger” be created to flag such projects. What followed was much back-and-forth on the review of the proposal as well as in TC meetings about how the tag name was negative and would hurt people’s feelings, how it would be seen as an attack against a project, that it was more of a stick rather than a carrot, etc. All of this hand-wringing over an objective measurement of the content of a project’s current level of activity. (Epilogue: they ended up making it a positive-sounding tag: “team:single-vendor”, and no tears were shed)
Having ineffective leadership like the TC has ripple effects throughout all of OpenStack. Each project is an island, and calls its own shots. So when two projects need to interact, they both see it from the perspective of “how will this affect me?” instead of “how will this improve OpenStack?”. This results in protracted discussions about interfaces and who will do what thing in what order. And when I say “protracted”, I don’t just mean weeks or months; some, such as the Cyborg–Nova integration discussions, have dragged on for two years! I cannot imaging that happening in a world with an OpenStack BDFL. This inter-project friction slows down development of OpenStack as a whole, and in my opinion, contributes to developer dissatisfaction.
So what would OpenStack have been like if it had had a BDFL? Of course, that would depend entirely on the individual, but I can say this: it would have flamed out very quickly with a poor BDFL, or it would be a much better product with a much higher adoption with a good one. Back in 2013 I had predicted that OpenStack would eventually rival the commercial clouds in much the same manner that Linux now dominates the internet over proprietary operating systems. In the early days of the internet, the ability for people to download and play with free software such as the LAMP stack enabled people with big ideas but small budgets to turn those ideas into reality. OpenStack began in the early days of cloud computing, and it seemed logical that having a freely-available alternative to the commercial clouds might likewise result in new cloud-native creations becoming reality. It was a believable prediction, but I missed the effect that a lack of coordination from above would have on OpenStack achieving the potential to fill that role.
By the way, many people point to Linux and its BDFL, Linus Torvalds, as the argument against having a BDFL, as Linus has repeatedly behaved as an offensive ass towards others when he didn’t like their ideas. But ass or not, Linux succeeded because of having that single opinion consistently shaping its development. Most BDFLs, though, are not insufferable asses, and their projects are better off as a result.
Immediately following the Open Infrastructure Summit in Denver was the 3-day Project Teams Gathering (PTG). This was the first time that these two events were scheduled back-to-back. It was in response to some members of the community complaining that traveling to 4 separate events a year (2 Summits, 2 PTGs) was both too expensive and too tiring. The idea was that now you would only have to travel twice a year.
Now that I’ve experienced these back-to-back events, I think that this was a giant step backwards. Let me explain why.
First, it was exhausting! Being in rooms with lots of people for days on end is very draining for those of us who are introverts. Sure, we can be outgoing and interact with people, but it takes a toll, and downtime is necessary to recharge the psychological batteries. At several points I found myself faced with attending a session or finding an empty room to work on stuff by myself, and the latter often won out.
Second, the main idea of the PTG was to take the midcycle get-togethers that many teams had been doing, and formalize a single place for them to meet. The feeling was that having these teams in the same place would spur cross-project discussions, and that definitely was the case. But now that teams will only be getting together every 6 months, we’re back to the situation we were in before the PTGs were created: many teams will need a mid-cycle meeting to ensure that everyone is on-track to complete the goals for that release cycle.
Third, being away from home for an entire week is too long. OK, maybe I’m just getting old, but I really do like being home. One of the nice things about traveling to conferences is tacking on a few extra days to explore the area. For example, after last year’s PTG in Denver, my wife flew out to join me, and we spent a long weekend in Rocky Mountain National Park and other nearby natural areas. But after a solid week of stuff, I couldn’t wait to go home.
Fourth, many people time their return travel so that they miss the last day (or part of it). My unscientific observation was that attendance on the last day of this PTG showed a more dramatic drop than in previous PTGs. I think that’s because it doesn’t seem as severe to miss one day out of 6 than to miss one day out of 3.
As is the tradition at PTGs, there was a feedback session at lunch on the second day, and a lot of the feedback was in line with my observations. Of course, there were a lot of people who liked the format, and for the exact opposite reasons! Goes to show you can’t please everyone.
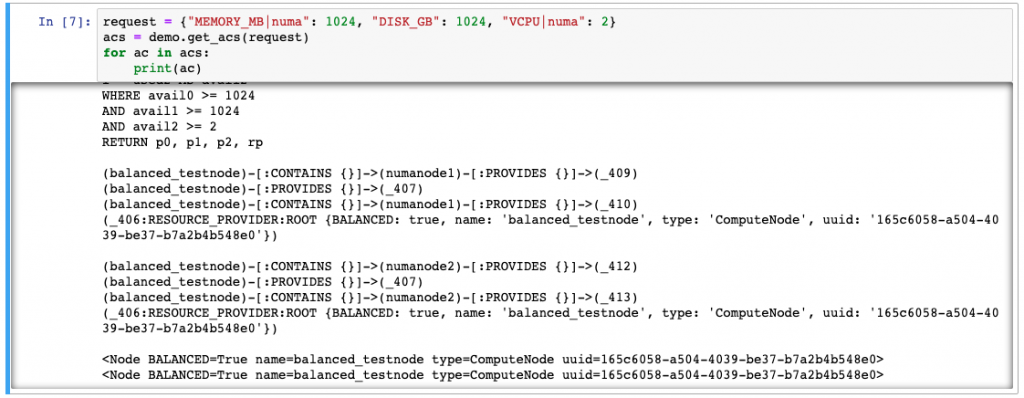
As for the sessions, the API-SIG was scheduled in a room for Thursday morning. I hung out there, and a few people did come in, but I think we had covered all of the outstanding issues at the BoF session on Tuesday. So I got to spend a lot of the morning hacking on Neo4j, and was able to implement a lot of the functionality that is missing in Placement: nested providers, shared providers, and quotas. I put together a series of Jupyter Notebooks that demonstrated all of these things working with just a small amount of code so that I could share with other people involved in Placement.
And then there was lunch! After 3 days of either going hungry or grabbing something nearby, it was so much nicer to sit down with people while eating lunch. Unfortunately, the box lunches provided seemed to have been kept at near-freezing temperatures until just before the lunch break, and almost too cold to eat. Still, I much preferred them to not having any lunch session at all, if for nothing else than being able to share a meal with other OpenStackers.
In the afternoon we had the Nova – Placement cross-project session, to which the Placement PTL, Chris Dent, brought some bottles of bubbly to celebrate the deletion of the Placement code base from Nova. That commit ended up getting delayed for one more day, but still, it was a milestone to celebrate.
The rest of the session was personally painful to sit through, as the topics revolved around the things that we have been fighting to implement for over 2.5 years: nested providers, shared providers, tree affinity, and other complex relationships among resources. It was painful because I just wanted to shout out “WE’RE USING THE WRONG TOOL!”, as these things naturally flowed from a graph database. I was able to get all of these things working in my spare time over the previous few days. I like to think that I’m a pretty smart guy, but I’m not THAT smart. It’s just because the tool fits the problem domain.
Jupyter notebook showing a section of the Nested Provider demo. It’s a little hard to see, but the two results show that there two possible solutions, both starting with the ComputeNode named ‘balanced_testnode’. Each solution shows that the requested resources both came from the same NUMA node. This is one of the things that comes naturally with a graph DB that is really, really hard in a SQL DB.
I spent that evening working to finish up my Neo4j examples, as I had asked several key placement contributors to take a few minutes to sit down with me so that I could show them what I had done. On Friday morning I showed my graph work to several people, and while each reaction was different, there was a definite flow from skepticism to curiosity and then (for some) to agreement. One of the people to whom I especially wanted to show this was Jay Pipes, whom I had mentioned in my earlier experiments with graph DBs. He had already seen the potential after those blog posts, but he was concerned with developers having to learn some new, cryptic language in order to implement this. However, after about 10 minutes of my demos, I showed him the query I was currently working on that wasn’t quite right. He looked it over, made a suggestion, and when I ran it, it worked correctly! So I think that if he could get a working knowledge after just 10 minutes of seeing the Cypher Query Language, it won’t be hard for other devs to pick it up.
Later in the day we had a good discussion with the Ironic team about a need that they had for stand-alone (i.e, not running under Nova). In such situations, they wanted to use the full resource amounts in placement, as opposed to the current approach used in Nova, which is to represent an Ironic node as an inventory of 1 thing. The issue with representing a baremetal server as, say, 500GB of disk and 16 CPUs is that it may occasionally be selected from a request for 250GB and 8CPU. Since each server cannot be shared, we needed to figure out a way to fully consume the resources on the machine when it was selected, even if the request was for a lower amount. Several ideas were floated and discussed, all with varying degrees of messiness. We finally settled on adding a new API endpoint that would accept a Resource Provider, and allocate all of its resources so that it would no longer be available to any other request.
Hallway Sign
On Saturday morning we started with the Cyborg-Nova cross-project session, at which we could finally see a demonstration of Cyborg in action! I had thought that the Summit sessions would have been much more useful if the demo had been shown then, so that we could have something concrete to discuss. I was glad to see that Cyborg is working and handling accelerators after a few years of planning and design, and I look forward to making further progress integrating it with Nova and Placement.
There were a few discussions in the afternoon that had to do with representing nested resources and their relationships. Once again, it was difficult to listen to these attempts to represent complex relationships in a SQL DB, when I had just demonstrated how simple it was in a graph DB. It was indeed telling that the subject was entitled “Implementing Nested Magic” – getting this working in SQL does seem to require supernatural powers!
I had to leave around 3pm to get to the airport, so I missed anything after that. But most people seemed to have left by then anyway. It had been a long week, and I was burnt out. I also missed being home with my wife, sleeping in my own bed, working at my own desk, and eating my own food. I sincerely hope that the Foundation reconsiders this back-to-back setup. I realize that they are trying to save money wherever possible, but this just wasn’t worth it.
Last week I was fortunate enough to participate in the OpenStack Summit, which was held in beautiful Vancouver, British Columbia. This is the second summit held in Vancouver, and for good reason: the facilities are first-class, and the location is one of the most beautiful you will find.
Vancouver Harbour reflected in the glass of the Convention Centre.
From the signage around the Convention Centre and the Keynote, the theme of the summit was clear: Open Infrastructure. The OpenStack Foundation is broadening its focus to not only include the OpenStack code itself, but also a range of technologies to deploy, run, and support modern data centers.
Open Infrastructure was the theme of the conference
The highlight (or maybe lowlight?) was the sponsored keynote by Mark Shuttleworth of Canonical. Generally speaking, companies which may be competitors in the marketplace but which work together to create OpenStack, put aside their differences and focus on their shared interests. Not Shuttleworth – he used the freedom that paying for that slot offered to badmouth both Red Hat and VMWare, claiming that Canonical can deliver OpenStack for a fraction of the cost of those two companies. While it’s likely true that OpenStack on Ubuntu would be less expensive than when running on a commercial distribution, the whole thing left a bad taste in everyone’s mouth. I know that this is typical Shuttleworth, but still… the spirit of coming together to collaborate took a big hit.
One thing I noticed was this slide that was presented showing how OpenStack supports “diverse architectures”.
Diverse… but no POWER? Guess IBM shouldn’t have dropped sponsorship!
Up until this summit, IBM had been a Platinum Member of the OpenStack Foundation, but greatly reduced its level of financial support recently. So it was a little curious that IBM’s architecture, POWER, was missing from this slide. Probably just an oversight, right?
After the keynotes, I went to the session by Belmiro Moreira of CERN, who spoke about CERN’s experience moving their large OpenStack deployment from Cells v1, to Cells v2 running in Pike. If you don’t know CERN, they run tens of thousands of servers in two data centers in order to support the research computations needed for the Large Hadron Collider. There is an inside joke among OpenStack developers when considering a change is whether it will help CERN or not – it’s sort of our performance test bed. Belmiro’s talk was very enlightening about just how these changes affected their performance. At first they had horrible results, but they were able to remedy them with config option changes as well as some horizontal scaling. In other words, it worked the way we had hoped it would: adjusting things that were designed to be adjusted, instead of having to hack around the code.
Another interesting session was the one discussing what would be needed to extract the Placement service from Nova into an independent project. The session was led by Chris Dent, who has done a lot of the prep work for the extraction. Nothing unexpected came from the session, which is a good thing; it showed that everyone on the Nova and Placement teams are in agreement on the path forward.
OpenStack in the house!
There was a session on Tuesday morning entitled “Revisiting Scalability and Applicability of OpenStack Placement“, by Yaniv Saar. There was some confusion on the subject, as the presenter used non-standard terminology, which was unfortunate; he used ‘placement’ to refer to the output of the Nova scheduler, not the Placement service itself. He had done extensive testing and statistical analysis to support his concept of a variation of the caching scheduler that only refreshed its cache after a given number of failures. The problem with this session was that all the work was done on the Mitaka code base, which pre-dates the creation of the Placement service. Most of the issues he “solved” have already been addressed by the Placement service, so his conclusions, while thoroughly backed up with numbers, dealt with a 3-year-old code base, and was irrelevant to the state of scheduling in Nova today.
Harbour Centre Reflection
After that was the API-SIG session (etherpad), where Gilles Dubreuil of Red Hat led the discussion about running a proof-of-concept for GraphQL. We discussed the various options for the best way to move forward with the PoC, with the principle that at the end (assuming success), we wanted a result that would be the most impressive to the OpenStack community, and possible persuade teams to adopt GraphQL. Gilles volunteered to lead this effort, and all of us in the API-SIG will be following closely to gauge the progress.
In the afternoon I went to the session on StarlingX, a new project from Wind River and Intel. I’m not up on all the history of this project, but it sure raised a lot of strong reactions among some long-time OpenStack people. As a result, I really don’t get the downside here; if you don’t want to support this code, well, just don’t support it. If there aren’t enough people who are interested, it will die a deserving death. If people do find some value there, then have at it.
Later in the afternoon I gave a talk along with Eric Fried on the state of the Placement service. Eric started by demonstrating that Placement isn’t just for Nova; it could be used to manage the groceries in your refrigerator! The examples were humorous, but did serve to show that the Placement service is agnostic about what sorts of resources you want to manage with it. I followed that with a recap of all the changes we had done in Queens and Rocky (so far), and what we are and will be working on in the future. I’ve gotten some positive feedback from people who attended the talk, so that makes me happy.
Convention Centre Entrance – no, that’s an actual globe they have hanging there.
Wednesday was light on sessions for me, because I had to take advantage of being in the same time zone as Tony Breeds of Red Hat, with whom I’m collaborating on some internal IBM-Red Hat stuff. We had been having some issues, and the half-day time difference made it hard to get any momentum. So I spent a good deal of the day working on the internal project with Tony.
Pixelated Orca
One session that was interesting was on API Debt Cleanup, which arose from an extended discussion on the openstack-dev mailing list. The advent of microversions has made adding to or changing an API smoother, but removing things that we no longer want to support is any easier. The consensus was that raising the minimum microversion that is supported should be signaled by a new major version. Some people on the dev side weren’t clear why they should keep supporting ancient, rusty parts of the code, but since there are SDKs that have been released that may use that code, we can’t ever assume that “no one uses this anymore”. Another part of the discussion was about making error codes/messages more consistent across projects. There were some proposed formats, but none that I feel provided any advantage over the existing API-SIG guideline on Error formats.
The view of Canada Place at night from the Convention Centre
Thursday was the final day of the summit. I spent a lot of it working on the internal IBM-Red Hat project with Tony, with the rest of it focused on the Technical Committee sessions. I haven’t been as active in TC matters since they switched from a regular weekly meeting to the Office Hours format, but I do try to keep up with things via the mailing list. I don’t have any particular insights to share with you here, but it was good to see that the TC is getting better at communicating what’s going on the to public, and that they are reacting to criticisms, real or perceived, of how and what they do. I was also encouraged by their acknowledgement of the lack of geographic diversity in their membership, and their desire to address that.
Of course, it’s not possible to travel to Vancouver, go to a conference, and just leave. So on Thursday evening I was joined by my wife, and thanks to the long holiday weekend (at least in the US), we got to enjoy both the city of Vancouver, as well as the natural beauty of the surrounding area. Let me close with a few photos from the beautiful Vancouver area. If the OpenStack Foundation announced another summit there, I will be the first to sign up!
Mountain views from Horseshoe Bay
Totems at Stanley Park
Selfie with Stawamus Chief Mountain in the distance