The recent spate of canceled conferences, sporting events, etc., due to concerns about spreading infection of the coronavirus COVID-19 has made me think about what will happen if these efforts are successful.
Back in the late 1990s, people realized that a lot of software written in the mid-20th century had a problem: due to the expense of storage, programmers shortened the way years were stored, so that something like 1978 would be stored as 78, with the century assumed. This was fine, but as that software aged, and the coming change of century approached, it was realized that many critical software problems would go from December 31, 1999, to January 1, 1900. This was the Year 2000 problem, commonly abbreviated as Y2K.
Having recognized the issue, most software companies invested heavily in updating their software to use full 4-digit representations for the year. It was tedious work; I personally had to write a series of tests for my projects that verified that things would continue to work in the year 2000. But because the warning was heeded, by the time that January 1, 2000 came most software had been updated. As a result, all of the doomsday scenarios (such as planes dropping from the sky) had been avoided. Yes, there were some billing glitches that were missed, but because of the intense efforts to address this problem, there were no serious problems.
What was the public’s reaction to this? Did they laud the developers for successfully averting a potential problem? Of course not. Instead, they reacted with disdain: “I thought this was going to be the end of the world! Nothing happened!”.
And that’s the point: because the warnings were heeded, and action was taken, nothing catastrophic happened. It didn’t mean that the problem wasn’t real; it just meant that the tech community understood the problem, and addressed it head-on.
So I’m wondering what will happen if the common-sense steps we are taking now to avoid spreading this virus ends up that not that many people get sick or die: will the Fox News people start complaining that it was all a politically-inspired hoax? That the liberal media tried to make Trump look bad by crying wolf? It almost makes me think that if there is a terrible body count, people will be ridiculed for taking ineffective steps, but if there isn’t such a terrible outcome, the steps that were taken will be ridiculed as overreaction, or, even worse, a political stunt.
Good question! It does seem unnecessary, especially since most major conferences record every talk and make them freely available online. PyCon has been doing this for many years, and are so good at it that the talks are available online shortly after they are finished! So there’s no real penalty for waiting until you can watch it online.
I suppose that if you look at tech conferences as simply dry tutorials on some new tool or technique, the answer would be “no, you should save your money and watch the sessions at home”. But there are much bigger benefits to attending a conference than just the knowledge available at the talks. I like to think of it as pressing the restart button on my thinking as a developer. By taking advantage of these additional avenues of learning, I come away with a different perspective on things: new tools, new ways of using existing tools, different approaches to solving development issues, and so much more that is intangible. Limiting yourself to the tangible resources of a conference means that you’re missing out. So what are these intangible things?
One of the most important is meeting people. Not so much to build your social network, but more to expand your understanding of different approaches to development. The people there may be strangers, but you know that you have at least one thing in common with them, so it’s easy to start conversations. I’ve been to 14 PyCons, and at lunch I make it a point to sit at tables where I don’t know anyone, and ask the people there “So what do you use Python for?”. Invariably they use it in ways that I had never thought about, or to solve problems that I had never worked on. The conversation can then move on to “Where are you from?”; people usually love to brag about their home town, and you might learn a few interesting things about a place you’ve never been to. Many people also go out to dinner in groups, usually with people who know each other, but I always try to look for people who are alone, and invite them to join our group.
Another major benefit of attending in person is what is known as the “hallway track”. These are the unscheduled discussions that occur in the hallways between sessions; sometimes they are a continuation of discussions that were held in a previous talk, and other times they are simply a bunch of people exchanging ideas. Some of the best technical takeaways I’ve gotten from conferences have come from these hallway discussions. When you’ve been to as many PyCons as I have, there are many people I run into who I haven’t seen since the last PyCon, and we can catch up on what’s new in each other’s lives and careers. Like the lunchtime table discussions, these are opportunities to learn about techniques and approaches that are different than what you regularly do.
Closely related to the above is the “bar track”. Most conferences have a main hotel for attendees, and in the evening you can find lots of people hanging out in the bar. The discussions there tend to have a bit less technical content, for obvious reasons, but I’ve been part of some very technical discussions where the participants are all on their third beer or so. But even if you don’t drink alcohol, you can certainly enjoy hanging out with your fellow developers in the evening. Or, of course, you can use that time to recharge your mental batteries.
Yet another opportunity at a conference is to enhance your career. There is usually some form of formal recruiting; if you’re looking for a change of career, this can be a valuable place to start. I’ve heard some managers say that they won’t send their developers to conferences because they are afraid that someone will hire them; it makes you wonder why they think their developers are not happy with their current job! But even if you’re not looking to make a career move at the moment, establishing relationships with others in your field can come in handy in the future if your job suddenly disappears. You can also learn what companies are looking for skills that match yours; I was surprised to learn that companies as diverse as Disney, Capital One, Yelp, and Bloomberg are all looking for Python talent. As an example, back at PyCon 2016 I met with some people recruiting for DataRobot, and while I didn’t pursue things then, they made a good impression on me. When I was looking for a change last year and got a LinkedIn message from a recruiter at DataRobot, I remembered them well, and this time I followed up, with the result that I’m now happily employed by DataRobot!
Unfortunately, I’ve seen people who arrive to a conference with a group of co-workers, attend the sessions, eat with each other at lunch, and then go out to dinner together. By isolating themselves and confining their learning to the scheduled talks, they are missing out on the most valuable part of attending a conference: interacting with your community, and sharing knowledge with your peers. If this sounds like you, I would advise you to try out some of the things I’ve mentioned here. I’m sure you will find that your conference experience is greatly improved!
A popular way of looking at the effort that someone with a chronic illness must expend to get through the day is Spoon Theory. It came about when the author, who has lupus, was in a restaurant trying to illustrate to her friends how she must ration her efforts to avoid exhaustion. She gathered spoons from nearby tables, gave them to her friend, and asked her to list the activities for a typical day. As her friend recited the activities she would have a spoon taken from her. Once those spoons were used up, any further effort that day would be nearly impossible.
This metaphor for expending limited resources has become very popular in communities for those with such chronic illnesses; some even refer to themselves as “spoonies”. I’ve also heard Spoon Theory applied to introverts, who can be in social situations for a much shorter time than others. I am an introvert, and I guess I could never quite feel that Spoon Theory was an accurate description of what my exhaustion felt like. I’m also a bit too literal at times, so the concept of somehow your spoons getting replenished didn’t seem realistic – is there some spoon delivery service? Spoons also don’t lend themselves to division: how would you spend half a spoon? Yes, I understand that this is all a metaphor, but effective metaphors should have clear connections to the reality they are describing. For it wasn’t just the simple passing of time that recharged me; it was how that time was spent made a huge difference in how quickly I could handle more activity among others.
One day I was hanging up a towel after a shower, and I thought about the cycle of use for a towel. A fresh towel can dry off a person who has just bathed, but there is a limited capacity any towel has for this. Once it has absorbed enough water, it can’t absorb any more. So after drying the person, the towel has to dry itself out. And it isn’t just the passing of time that is needed, but also proper placement of the towel. Leaving the towel balled up on the floor would require a very long time for the towel to fully dry; it would probably get mildewed first! But if you were to hang it up so that air is able to circulate around it, it will be dry much more quickly. And if you hung it on a clothesline outside in the sun on a breezy day, it would be dry in no time at all!
Towels also come in different sizes and materials, both of which affect its capacity to absorb water. The drying task that the towel is used for also affects its usefulness: drying a hand here and there would never saturate it, but being wrapped around someone stepping out of a pool soaking wet would test its limits.
Introverts are like smaller towels that more quickly reach their limit absorbing social interactions. My experience attending tech conferences seems to mirror the cycle of towels. If I’m listening to sessions, with only occasional interactions, I can go all day. If I’m involved in lots of discussion-type sessions, I can’t go nearly as long. If I’m giving a talk, that’s even more draining. And when I’m staffing a booth, where I need to be constantly talking with all sorts of people, I run out of energy much more quickly. For a towel, that would be like being held under a running faucet: it loses its ability to dry very quickly.
How I “hang myself up” also determines how quickly I recover. I can sit in a corner of the conference and work on my laptop, but it’s much better if I can work in my room where there are no other people walking around. And what seems to work best for me is to go outside and walk around: the movement, the fresh air, the different visual scenery – all that helps me feel more energized. The last few years I have made it a practice that, weather permitting, I find a block of time toward the middle of the day, and go outside walking with my camera. Being a photographer, I can often get some good opportunities, no matter where the conference is held. And it seems that focusing my brain on creativity for an hour or so allows me to feel energized and able to immerse myself back into the conference events. It’s like a clothesline in the sun for my towel!
So I hope that Towel Theory does as much to help people understand what the introvert experience is like as Spoon Theory has done to help illustrate the situation of people with chronic illnesses.
Immediately following the Open Infrastructure Summit in Denver was the 3-day Project Teams Gathering (PTG). This was the first time that these two events were scheduled back-to-back. It was in response to some members of the community complaining that traveling to 4 separate events a year (2 Summits, 2 PTGs) was both too expensive and too tiring. The idea was that now you would only have to travel twice a year.
Now that I’ve experienced these back-to-back events, I think that this was a giant step backwards. Let me explain why.
First, it was exhausting! Being in rooms with lots of people for days on end is very draining for those of us who are introverts. Sure, we can be outgoing and interact with people, but it takes a toll, and downtime is necessary to recharge the psychological batteries. At several points I found myself faced with attending a session or finding an empty room to work on stuff by myself, and the latter often won out.
Second, the main idea of the PTG was to take the midcycle get-togethers that many teams had been doing, and formalize a single place for them to meet. The feeling was that having these teams in the same place would spur cross-project discussions, and that definitely was the case. But now that teams will only be getting together every 6 months, we’re back to the situation we were in before the PTGs were created: many teams will need a mid-cycle meeting to ensure that everyone is on-track to complete the goals for that release cycle.
Third, being away from home for an entire week is too long. OK, maybe I’m just getting old, but I really do like being home. One of the nice things about traveling to conferences is tacking on a few extra days to explore the area. For example, after last year’s PTG in Denver, my wife flew out to join me, and we spent a long weekend in Rocky Mountain National Park and other nearby natural areas. But after a solid week of stuff, I couldn’t wait to go home.
Fourth, many people time their return travel so that they miss the last day (or part of it). My unscientific observation was that attendance on the last day of this PTG showed a more dramatic drop than in previous PTGs. I think that’s because it doesn’t seem as severe to miss one day out of 6 than to miss one day out of 3.
As is the tradition at PTGs, there was a feedback session at lunch on the second day, and a lot of the feedback was in line with my observations. Of course, there were a lot of people who liked the format, and for the exact opposite reasons! Goes to show you can’t please everyone.
As for the sessions, the API-SIG was scheduled in a room for Thursday morning. I hung out there, and a few people did come in, but I think we had covered all of the outstanding issues at the BoF session on Tuesday. So I got to spend a lot of the morning hacking on Neo4j, and was able to implement a lot of the functionality that is missing in Placement: nested providers, shared providers, and quotas. I put together a series of Jupyter Notebooks that demonstrated all of these things working with just a small amount of code so that I could share with other people involved in Placement.
And then there was lunch! After 3 days of either going hungry or grabbing something nearby, it was so much nicer to sit down with people while eating lunch. Unfortunately, the box lunches provided seemed to have been kept at near-freezing temperatures until just before the lunch break, and almost too cold to eat. Still, I much preferred them to not having any lunch session at all, if for nothing else than being able to share a meal with other OpenStackers.
In the afternoon we had the Nova – Placement cross-project session, to which the Placement PTL, Chris Dent, brought some bottles of bubbly to celebrate the deletion of the Placement code base from Nova. That commit ended up getting delayed for one more day, but still, it was a milestone to celebrate.
The rest of the session was personally painful to sit through, as the topics revolved around the things that we have been fighting to implement for over 2.5 years: nested providers, shared providers, tree affinity, and other complex relationships among resources. It was painful because I just wanted to shout out “WE’RE USING THE WRONG TOOL!”, as these things naturally flowed from a graph database. I was able to get all of these things working in my spare time over the previous few days. I like to think that I’m a pretty smart guy, but I’m not THAT smart. It’s just because the tool fits the problem domain.
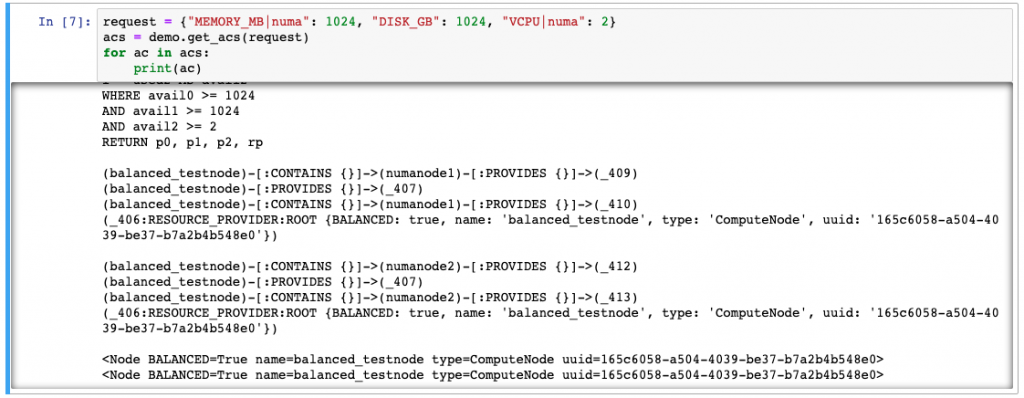
Jupyter notebook showing a section of the Nested Provider demo. It’s a little hard to see, but the two results show that there two possible solutions, both starting with the ComputeNode named ‘balanced_testnode’. Each solution shows that the requested resources both came from the same NUMA node. This is one of the things that comes naturally with a graph DB that is really, really hard in a SQL DB.
I spent that evening working to finish up my Neo4j examples, as I had asked several key placement contributors to take a few minutes to sit down with me so that I could show them what I had done. On Friday morning I showed my graph work to several people, and while each reaction was different, there was a definite flow from skepticism to curiosity and then (for some) to agreement. One of the people to whom I especially wanted to show this was Jay Pipes, whom I had mentioned in my earlier experiments with graph DBs. He had already seen the potential after those blog posts, but he was concerned with developers having to learn some new, cryptic language in order to implement this. However, after about 10 minutes of my demos, I showed him the query I was currently working on that wasn’t quite right. He looked it over, made a suggestion, and when I ran it, it worked correctly! So I think that if he could get a working knowledge after just 10 minutes of seeing the Cypher Query Language, it won’t be hard for other devs to pick it up.
Later in the day we had a good discussion with the Ironic team about a need that they had for stand-alone (i.e, not running under Nova). In such situations, they wanted to use the full resource amounts in placement, as opposed to the current approach used in Nova, which is to represent an Ironic node as an inventory of 1 thing. The issue with representing a baremetal server as, say, 500GB of disk and 16 CPUs is that it may occasionally be selected from a request for 250GB and 8CPU. Since each server cannot be shared, we needed to figure out a way to fully consume the resources on the machine when it was selected, even if the request was for a lower amount. Several ideas were floated and discussed, all with varying degrees of messiness. We finally settled on adding a new API endpoint that would accept a Resource Provider, and allocate all of its resources so that it would no longer be available to any other request.
Hallway Sign
On Saturday morning we started with the Cyborg-Nova cross-project session, at which we could finally see a demonstration of Cyborg in action! I had thought that the Summit sessions would have been much more useful if the demo had been shown then, so that we could have something concrete to discuss. I was glad to see that Cyborg is working and handling accelerators after a few years of planning and design, and I look forward to making further progress integrating it with Nova and Placement.
There were a few discussions in the afternoon that had to do with representing nested resources and their relationships. Once again, it was difficult to listen to these attempts to represent complex relationships in a SQL DB, when I had just demonstrated how simple it was in a graph DB. It was indeed telling that the subject was entitled “Implementing Nested Magic” – getting this working in SQL does seem to require supernatural powers!
I had to leave around 3pm to get to the airport, so I missed anything after that. But most people seemed to have left by then anyway. It had been a long week, and I was burnt out. I also missed being home with my wife, sleeping in my own bed, working at my own desk, and eating my own food. I sincerely hope that the Foundation reconsiders this back-to-back setup. I realize that they are trying to save money wherever possible, but this just wasn’t worth it.
The first ever Open Infrastructure Summit was held in the last week of April 2019 at the Colorado Convention Center in Denver, CO. It’s the first since the re-branding from OpenStack to Open Infrastructure began last year to be officially held with the new name. Otherwise, it felt just like the OpenStack summits of old.
The keynotes were better than in prior summits – I think the sponsors got the feedback that no one was interested in sitting through a recap of “how they did X with OpenStack”, and instead focused more on what they intended to do with it. There was a great demo by Chris Hoge and Julia Kreger that showed a kubernetes operator managing a bare metal infrastructure; it showed very clearly that the typical media message around “Kubernetes is replacing OpenStack” is silly. They exist in different problem spaces, and work well together. The only place Kubernetes is replacing OpenStack is in the hype cycle.
After the keynotes I went to the Nova Project Update session. It was very thorough, but felt more like someone reading release notes out loud. I had hoped for more of a discussion about the thinking that went into some of the things that were worked on or are being planned rather than just a straight recitation.
After that was lunch – sort of. For the first time since these summits began, lunch was not provided. Instead, you were supposed to go to one of the many restaurants in the area and buy your own lunch. However, since we had pretty poor weather—freezing temperatures, snow, and rain—walking around downtown Denver wasn’t what I felt like doing. Judging by how packed the restaurant in the hotel across the street was, a lot of other people felt the same way. I understand that times are not as heady as in previous years when OpenStack was the latest hotness, but this seemed like a poor place to cut back. I always enjoyed sharing a table with a bunch of other OpenStackers and learning about where they were from and what they were doing with OpenStack. Going out to lunch meant that people tended to stay with groups they already knew. The afternoon snacks were also gone, which is no big deal for me, but others mentioned to me that they missed having them. Finally, they didn’t have a signature piece of conference swag. I’m typing this wearing the OpenStack hoodie I got back in the Paris 2014 summit, and have my sweatshirt from Tokyo 2015 in my room. Well, OK, they did give out a pair of socks, but they weren’t tied to the event. It’s not a huge thing, but not having something this time really makes things feel… different. And not in a good way.
There weren’t any sessions in the afternoon that I really wanted to go to, so instead I worked on two OpenStack-related projects: etcd-compute and using Graph Databases, such as Neo4j, to hold information for the Placement service. I have previously written about my work with both of these. And since the author of etcd-compute, Chris Dent, was also here at the summit, it was a perfect time to work on it together, so I set up several VMs for us to “play with”.
Monday evening after the sessions was the “Marketplace Mixer”, which is a way to get the attendees to visit the vendor area. They provided food and beverages, and I had my badge scanned several times in exchange for some local craft beer. There wasn’t a lot offered by the vendors that would be useful to me, but I did run into a lot of people I knew. When you’re in your 10th year of working on OpenStack, you get to know quite a few people!
On Tuesday I started with a session on Nova-Cyborg integration. Or at least that was what it was advertised as. It turned out to be more of an “Introduction to Cyborg Concepts” talk, rather than focusing on where the two projects needed to integrate.
The crowd at the Cyborg-Nova integration session
Later on was the API-SIG BoF (Birds of a Feather) session that I headed up. There hadn’t been much traffic in the SIG ahead of the summit, so I was happily surprised when several people showed up. We ended up having a good discussion on a variety of API-related topics, and I got to meet several of the people who have joined in some of the more recent IRC discussions and Office Hours who previously I had only known by their IRC handles. It’s always nice to put a face to a name.
In the afternoon was a session to update everyone on the process of extracting Placement from Nova. In the past this has been a somewhat heated topic, but this time everyone seemed to understand where things were and were pretty cool with it. There weren’t any long discussions, so the session finished early. I guess that’s a very good sign that we handed that process well.
The final session of the afternoon was to discuss what the various SIGs (Special Interest Groups) and WGs (Working Groups) needed to be successful. Since the API-SIG has been around for many years, we didn’t really have any needs along these lines. Sure, it would be great to get more people involved, but it isn’t critical. Some of the newer groups explored ways of getting the word out about their existence, which is always a problem. There is so much going on in the OpenStack world that getting people to pay attention to yet another thing is always challenging.
That evening was the Open Infrastructure party, sponsored by Trilio, Mirantis, Red Hat, Open Telekom Cloud, & AVI Networks. It was held in The Church Nightclub, which is an old church that has been converted to a nightclub. There was an open bar and food available, and they had a band playing for entertainment. The location was fun, but being indoors with loud music meant that there was only so much conversation you could have. Still, it was fun!
The crowd at the Open Infrastructure Party at the Church Niteclub
A view from higher up that shows how an old church was converted into a niteclub. You can see the some of the band playing at the very bottom.
There weren’t any talks on Wednesday morning that I really wanted to attend, so I spent most of the morning in the designated hacking room working on the etcd-compute project for a while, and then on implementing many of the features that are currently lacking in Placement in my graph database code. I managed to implement passing a tree structure to represent nested resource providers so that it creates the corresponding nodes and relationships in the database. This implementation is becoming more and more complete, and I hope when I show it to others this week that they are able to get out of their MySQL comfort zone and see how much better this approach is for representing resources.
I went to lunch with some of the members of my team at IBM who were at the Summit, along with some people from Red Hat with whom we are working to ensure that their various offerings run as well on Power hardware as on x86. So while the pizza was tasty, it was definitely a working lunch. It was also great to meet some of the people I had only known online before.
The Red Hat – IBM lunch *after* the food had been eaten.
After lunch was a session focused on the gaps between Nova functionality and what has been implemented in OpenStack Client. Most of the missing functionality is concerned with supporting new microversions, and this support is several years behind. I’m not sure how effective the discussions were, since what is really needed is for people to take ownership of some of the needed tasks, and I didn’t hear a lot of that happening.
After that I went to the Cyborg Project Update. Once again, it probably would have been much more useful to anyone who hadn’t been following along with the project, so while I didn’t get much from it, there was a lot of information presented on the current state and future plans for Cyborg.
And that was it! The end of another Summit, even if it was the first. That evening I met my sister for dinner. She lives in the Denver area, and it was great to catch up with her and spend some time relaxing after 3 long days. But the relaxation will be short-lived, as the Train PTG starts first thing tomorrow morning!