
Immediately following the Open Infrastructure Summit in Denver was the 3-day Project Teams Gathering (PTG). This was the first time that these two events were scheduled back-to-back. It was in response to some members of the community complaining that traveling to 4 separate events a year (2 Summits, 2 PTGs) was both too expensive and too tiring. The idea was that now you would only have to travel twice a year.
Now that I’ve experienced these back-to-back events, I think that this was a giant step backwards. Let me explain why.
First, it was exhausting! Being in rooms with lots of people for days on end is very draining for those of us who are introverts. Sure, we can be outgoing and interact with people, but it takes a toll, and downtime is necessary to recharge the psychological batteries. At several points I found myself faced with attending a session or finding an empty room to work on stuff by myself, and the latter often won out.
Second, the main idea of the PTG was to take the midcycle get-togethers that many teams had been doing, and formalize a single place for them to meet. The feeling was that having these teams in the same place would spur cross-project discussions, and that definitely was the case. But now that teams will only be getting together every 6 months, we’re back to the situation we were in before the PTGs were created: many teams will need a mid-cycle meeting to ensure that everyone is on-track to complete the goals for that release cycle.
Third, being away from home for an entire week is too long. OK, maybe I’m just getting old, but I really do like being home. One of the nice things about traveling to conferences is tacking on a few extra days to explore the area. For example, after last year’s PTG in Denver, my wife flew out to join me, and we spent a long weekend in Rocky Mountain National Park and other nearby natural areas. But after a solid week of stuff, I couldn’t wait to go home.
Fourth, many people time their return travel so that they miss the last day (or part of it). My unscientific observation was that attendance on the last day of this PTG showed a more dramatic drop than in previous PTGs. I think that’s because it doesn’t seem as severe to miss one day out of 6 than to miss one day out of 3.
As is the tradition at PTGs, there was a feedback session at lunch on the second day, and a lot of the feedback was in line with my observations. Of course, there were a lot of people who liked the format, and for the exact opposite reasons! Goes to show you can’t please everyone.
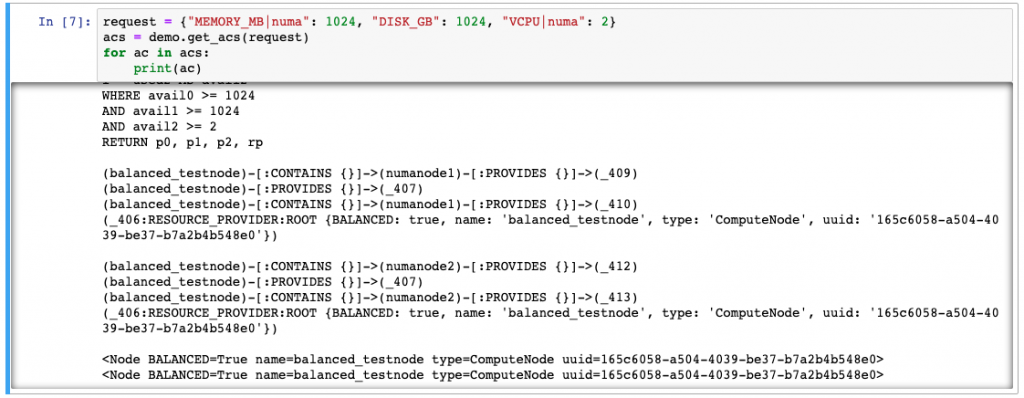
As for the sessions, the API-SIG was scheduled in a room for Thursday morning. I hung out there, and a few people did come in, but I think we had covered all of the outstanding issues at the BoF session on Tuesday. So I got to spend a lot of the morning hacking on Neo4j, and was able to implement a lot of the functionality that is missing in Placement: nested providers, shared providers, and quotas. I put together a series of Jupyter Notebooks that demonstrated all of these things working with just a small amount of code so that I could share with other people involved in Placement.
And then there was lunch! After 3 days of either going hungry or grabbing something nearby, it was so much nicer to sit down with people while eating lunch. Unfortunately, the box lunches provided seemed to have been kept at near-freezing temperatures until just before the lunch break, and almost too cold to eat. Still, I much preferred them to not having any lunch session at all, if for nothing else than being able to share a meal with other OpenStackers.
In the afternoon we had the Nova – Placement cross-project session, to which the Placement PTL, Chris Dent, brought some bottles of bubbly to celebrate the deletion of the Placement code base from Nova. That commit ended up getting delayed for one more day, but still, it was a milestone to celebrate.
The rest of the session was personally painful to sit through, as the topics revolved around the things that we have been fighting to implement for over 2.5 years: nested providers, shared providers, tree affinity, and other complex relationships among resources. It was painful because I just wanted to shout out “WE’RE USING THE WRONG TOOL!”, as these things naturally flowed from a graph database. I was able to get all of these things working in my spare time over the previous few days. I like to think that I’m a pretty smart guy, but I’m not THAT smart. It’s just because the tool fits the problem domain.
I spent that evening working to finish up my Neo4j examples, as I had asked several key placement contributors to take a few minutes to sit down with me so that I could show them what I had done. On Friday morning I showed my graph work to several people, and while each reaction was different, there was a definite flow from skepticism to curiosity and then (for some) to agreement. One of the people to whom I especially wanted to show this was Jay Pipes, whom I had mentioned in my earlier experiments with graph DBs. He had already seen the potential after those blog posts, but he was concerned with developers having to learn some new, cryptic language in order to implement this. However, after about 10 minutes of my demos, I showed him the query I was currently working on that wasn’t quite right. He looked it over, made a suggestion, and when I ran it, it worked correctly! So I think that if he could get a working knowledge after just 10 minutes of seeing the Cypher Query Language, it won’t be hard for other devs to pick it up.
Later in the day we had a good discussion with the Ironic team about a need that they had for stand-alone (i.e, not running under Nova). In such situations, they wanted to use the full resource amounts in placement, as opposed to the current approach used in Nova, which is to represent an Ironic node as an inventory of 1 thing. The issue with representing a baremetal server as, say, 500GB of disk and 16 CPUs is that it may occasionally be selected from a request for 250GB and 8CPU. Since each server cannot be shared, we needed to figure out a way to fully consume the resources on the machine when it was selected, even if the request was for a lower amount. Several ideas were floated and discussed, all with varying degrees of messiness. We finally settled on adding a new API endpoint that would accept a Resource Provider, and allocate all of its resources so that it would no longer be available to any other request.

On Saturday morning we started with the Cyborg-Nova cross-project session, at which we could finally see a demonstration of Cyborg in action! I had thought that the Summit sessions would have been much more useful if the demo had been shown then, so that we could have something concrete to discuss. I was glad to see that Cyborg is working and handling accelerators after a few years of planning and design, and I look forward to making further progress integrating it with Nova and Placement.
There were a few discussions in the afternoon that had to do with representing nested resources and their relationships. Once again, it was difficult to listen to these attempts to represent complex relationships in a SQL DB, when I had just demonstrated how simple it was in a graph DB. It was indeed telling that the subject was entitled “Implementing Nested Magic” – getting this working in SQL does seem to require supernatural powers!
I had to leave around 3pm to get to the airport, so I missed anything after that. But most people seemed to have left by then anyway. It had been a long week, and I was burnt out. I also missed being home with my wife, sleeping in my own bed, working at my own desk, and eating my own food. I sincerely hope that the Foundation reconsiders this back-to-back setup. I realize that they are trying to save money wherever possible, but this just wasn’t worth it.