Last week was the OpenStack Summit, which was held in Sydney, NSW, Australia. This was my first summit since the split with the PTG, and it felt very different than previous summits. In the past there was a split between the business community part of the summit and the Design Summit, which was where the dev teams met to plan the work for the upcoming cycle. With the shift to the PTG, there is no move developer-centric work at the summit, so I was free to attend sessions instead of being buried in the Nova room the whole time. That also meant that I was free to explore the hallway track more than in the past, and as a result I had many interesting conversations with fellow OpenStackers.
There was also only one keynote session on Monday morning. I found this a welcome change, because despite getting some really great information, there are the inevitable vendor keynotes that bore you to tears. Some vendors get it right: they showed the cool scientific research that their OpenStack cloud was enabling, and knowing that I’m helping to make that happen is always a positive feeling. But other vendors just drone about things like the number of cores they are running, and the tools that they use to get things running and keep them running. Now don’t get me wrong: that’s very useful information, but it’s not keynote material. I’d rather see it written up on their website as a reference document.
A view of the audience for Monday’s keynote
On Monday after the keynote we had a lively session for the API-SIG, with a lot of SDK developers participating. One issue was that of keeping up with API changes and deprecating older API versions. In many cases, though, the reason people use an SDK is to be insulated from that sort of minutiae; they just want it to work. Sometimes that comes at a price of not having access to the latest features offered by the API. This is where the SDK developer has to determine what would work best for their target users.
Chris Dent getting ready to start the API-SIG sessionMany of the attendees of the API-SIG session
Another discussion was how to best use microversions within an SDK. The consensus was to pin each request to the particular microversion that provides the desired functionality, rather than make all requests at the same version. There was a suggestion to have aliases for the latest microversion for each release; e.g., “OpenStack-API-Version: compute pike” would return the latest behaviors that were available for the Nova Pike release. This idea was rejected, as it dilutes the meaning and utility of what a microversion is.
On the Tuesday I helped with the Nova onboarding session, along with Dan Smith and Melanie Witt. We covered things like the layout of code in the Nova repository, and also some of the “magic” that handles the RPC communication among services within Nova. While the people attending seemed to be interested in this, it was hard to gauge the effectiveness for them, as we got precious few questions, and those we did get really didn’t have much to do with what we covered.
That evening the folks from Aptira hired a fairly large party boat, and invited several people to attend. I was fortunate enough to be invited along with my wife, and we had a wonderful evening cruising around Sydney Harbour, with some delicious food and drink provided. I also got to meet and converse with several other IBMers.
The Clearview Glass Boat for the Aptira party getting ready to board passengersLinda and I enjoying ourselves aboard the Aptira Sydney Harbour Cruise.We enjoyed the food and drink!Talking with a group of IBMers. It looks like I’m lecturing them!
There were other sessions I attended, but mostly out of curiosity about the subject. The only other session with anything worth reporting was with the Ironic team and their concerns about the change to scheduling by resource classes and traits. There was still a significant lack of understanding about how this will work for many in the room, which I interpret to mean that we who are creating the Placement service are not communicating this well enough. I was glad that I was able to clarify several things for those who had concerns, and I think that everyone had a better understanding of both how things are supposed to work, as well as what will be required to move their deployments forward.
One development I was especially interested in was the announcement of OpenLab, which will be especially useful for testing SDKs across multiple clouds. Many people attending the API-SIG session thought that they would want to take advantage of that for their SDK work.
My overall impression of the new Summit format is that, as a developer, it leaves a lot to be desired. Perhaps it was because the PTGs have become the place where all the real development planning happens, and so many of the people who I normally would have a chance to interact with simply didn’t come. The big benefit of in-person conferences is getting to know the new people who have joined the project, and re-establishing ties with those with whom you have worked for a while. If you are an OpenStack developer, the PTGs are essential; the Summits, no so much. It will be interesting to see how this new format evolves in the future.
If you’re interested in more in-depth coverage of what went on at the Summit, be sure to read the summary from Superuser.
The location was far away for me, but Sydney was wonderful! We took a few days afterwards to holiday down in Hobart, Tasmania, which made the long journey that much more worth the effort.
Panoramic view of Darling Harbour from my hotel. The Convention Centre is on the right.
This seems so simple that it should be obvious, but it apparently it’s not, so I guess I have to spell it out. When waiting at a baggage claim carousel, you should stand back a few feet until you see your bag. Not only does it make it easier for everyone to get a view of the bags, but it leaves room for unloading the bags. Don’t crowd the carousel like these people:
One guy has the right idea, but he can’t see the bags that are coming because the others are blocking his view.
On a recent flight I saw my bag coming around , and had to squeeze my way through the people crowding the carousel. When it came, I grabbed it and lifted it off in order to put it on the ground. In the process it struck one of the people crowding the area, and he gave me a dirty look. I gave him one right back. It’s simply rude not to give a fellow traveler enough room to retrieve their luggage, and when you see someone grabbing their bag, it’s up to you to get out of their way.
Are you numb yet? To all of the outrageous, dishonest, and self-serving things that Donald Trump does? Or does your blood still boil every time his name is mentioned? I find myself in the latter camp, but I’m here to remind you of something very important: Trump Is Not The Enemy.
He is an enemy, of course, but by focusing on him, we miss the bigger picture. Thought experiment: imagine that tomorrow morning you wake up to see that Trump has tweeted his resignation. He’s gone. Not only that, but Bob Mueller also announces indictments of Trump Sr., Trump Jr., and Ivanka Trump. They’re all going to prison for a long, long time. Would that mean that things will be all right again?
Hardly. The Republican party controls all 3 branches of government, and they have been more than happy to ride along with the Trump populist train in order to achieve their goals. They have confirmed nominees to cabinet posts who are not only unqualified, but who have expressed views that are 180° opposed to the office they occupy. They have tried to take away health care to millions of people, and are currently planning on redistributing even more of the income of the masses to the extremely wealthy. They have wantonly ignored the truth, and instead parroted Fox News talking points. If Trump were to disappear, we’d have President Mike Pence, who would gladly continue, if not accelerate, the decline of our country.
It is not Trump, but the Republican party that is the true enemy. The only way we can progress as a country is to remove them from power.
How do we do that? My suggestion is to tie everything that Trump does to Republicans. If Trump hints about nuking North Korea or killing gay people, don’t place the blame solely on him. Place it on the enablers. Place it on the Republicans. Hold them accountable.
There are several Republicans in Congress who have expressed privately that they feel that Trump is unstable, but instead of acting on that, they just let it continue. Hold them accountable.
There is an overwhelming track record of violating the emoluments clause, and personally profiting from government use of his properties, but the Republicans turn a blind eye to that. Hold them accountable.
If in the weeks to come, evidence of Trump’s collusion with Russia surfaces, or any of a number of other potentially impeachable offenses are revealed, the power to impeach is 100% in the hands of the Republican majority. If they don’t act as swiftly and as thoroughly as they did investigating Hillary Clinton for Benghazi, they are excusing those acts, and thus complicit. Make that the headline, and hold them accountable.
We need to constantly tie our outrage to the Republicans, and not just to Trump, if we ever hope to move this country back to a positive direction. We need to stop focusing on winning the White House, and focus instead on winning state legislatures so that we can undo the gerrymandering that has allowed them to control the House with a minority of votes. We need to be sure to target every single Republican who is up for re-election in 2018, and tie them inextricably to Donald Trump. Trump is going down in flames, and we need to bring all of his enablers down with him.
Last week was the second-ever OpenStack Project Teams Gathering, or PTG. It’s still an awkward name for a very productive conference.
This time the PTG was held in Denver, Colorado, at a hotel several miles outside of downtown Denver.
Downtown Denver, as seen from the PTG hotel. We were about 8 miles away.
It was clear that the organizers from the OpenStack Foundation took the comments from the attendees of the first PTG in Atlanta to heart, as it seemed that none of the annoyances from Atlanta were an issue: there was no loud air conditioning, and the rooms were much less echo-y. The food was also a lot better!
On Friday, the lunch offering featured a custom Mac & Cheese station, where you could select from shrimp, ham, or chicken, and then add your choice of cheeses.
As in Atlanta, Monday and Tuesday were set aside for cross-project sessions, with team sessions on Wednesday–Friday. Most of the first two days was taken up by the API-SIG discussions. There was a lot to talk about, and we managed to cover most of it. One main focus was how to expand our outreach to various groups, now that we have transitioned from a Working Group (WG) to a Special Interest Group (SIG). That may sound like a simple name change, but it represents the shift in direction from being only API developer-focused to reaching out to SDK developers and users.
For the API-SIG discussions, the arrangement of tables spread us too far apart, so we took matters into our own hands
We discussed several issues that had been identified ahead of time. The first was the format for single resources. The format for multiple resources has not been contentious; it looks like:
In English, a list of the returned resources in a dictionary with the resource type/name as the key. But for a single resource, there are several possibilities:
# Singular resource
{resource}
# One-element list
[{resource}]
# Dictionary keyed by resource name, single value
{"resource_name": {resource}}
# Dictionary keyed by resource name, list of one value
{"resource_name": [{resource}]}
None of these stood out as a clear winner, as we could come up with pros and cons for each. When that happens, we make consistency with the rest of OpenStack a priority, so elmiko agreed to survey the code base to get some numbers. If there is a clear preference within OpenStack, we can make that the recommended form.
Next was a very quick discussion of the microversion-parse library, and whether we should recommend it as an “official” tool for projects to use (we did). This would mean that the API-SIG would be undertaking ownership of the library, but as it’s very simple, this was not felt to be a significant burden.
We moved on to the topic of API testing tools. This idea had come up in the past: create a tool that would check how well an API conformed to the guidelines. We agreed once again that that would be a huge effort with very little practical benefit, and that we would not entertain that idea again.
Next up were some people from the Ironic team who had questions about what we would recommend for an API call that was expected to take a long time to complete. Blocking while the call completes could take several minutes, so that was not a good option. The two main options were to use a GET with an “action” as the resource, or POST with the action in the body. Using GET for this doesn’t fit well with RESTful principles, so POST was really the only option, as it is semantically fluid. The response should be a 202 Accepted, and contain the URI that can be called with GET to determine the status of the request. The Ironic team agreed to write up a more detailed description of their use case, which the API-SIG could then use as the base for an example of a guided review discussion.
Another topic that got a lot of discussion was Capabilities. This term is used in many contexts, so we were sure to distinguish among them.
What is this cloud capable of doing?
What actions are possible for this particular resource?
What actions are possible for this particular authenticated user?
We focused on the first type of capability, as it is important for cloud interoperability. There are ways to determine these things, but they might require a dozen API calls to get the information needed. There already is a proposal for creating a static file for clouds, so perhaps this can be expanded to cover all the capabilities that may be of interest to consumers of multiple clouds. This sort of root document would be very static and thus highly cacheable.
For the latter two types of capabilities, it was felt that there was no alternative to making the calls as needed. For example, a user might be able to create an instance of a certain size one minute, but a little later they would not because they’ve exceeded their quota. So for user interfaces such as Horizon, where, say, a button in the UI might be disabled if the user cannot perform that action, there does not seem to be a good way to simplify things.
We spent a good deal of time with a few SDK authors about some of the issues they are having, and how the API-SIG can help. As someone who works on the API creation side of things but who has also created an SDK, these discussions were of particular interest. Since this topic is fairly recent, most of the time was spent getting a feel for the issues that may be of interest. There was some talk of creating SDK guidelines, similar to the API guidelines, but that doesn’t seem like the best way to go. APIs have to be consumed by all sorts of different applications, so consistency is important. SDKs, on the other hand, are consumed by developers for that particular language. The best advice is to make your SDK as idiomatic as possible for the language so that the developers using your SDK will find it as usable as the rest of the language.
After the sessions on Tuesday, there was a pleasant happy hour, with the refreshments sponsored by IBM. It gave everyone a chance to talk to each other, and I had several interesting conversations with people working on different parts of OpenStack.
The Tuesday happy hour featured beer and wine, courtesy of IBM!
Starting Wednesday I was in the Nova room for most of the time. The day started off with the Pike retrospective, where we ideally take a look at how things went during the last cycle, and identify the things that we could do better. This should then be used to help make the next cycle go more smoothly. The Nova team can certainly be pretty dysfunctional at times, and in past retrospectives people have tried to address that. But rather than help people understand the effects of their actions better, such comments were typically met by sheer defensiveness, and as a result none of the negative behaviors changed. So this time no one brought up the problems with personal interactions, and we settled on a vague “do shit earlier” motto. What this means is that some people felt that the spec process dragged on for much too long, and that we would be better off if we kept that short and started coding sooner. No process for cutting short the time spent on specs was discussed, though, so it isn’t clear how this will be carried out. The main advantage of coding sooner is that many of these changes will break existing behaviors, and it is better to find that out early in the cycle rather than just before freeze. The downside is that we may start down a particular path early, and due to shortening the spec process, not realize that it isn’t the right (or best) path until we have already written a bunch of code. This will most likely result in a sunk cost fallacy argument in favor of patching the code and taking on more technical debt. Let’s hope that I’m wrong about this.
We moved on to Cells V2. On of the top priorities is listing instances in a multi-cell deployment. One proposed solution was to have Searchlight monitor instance notifications from the cells, and aggregate that information so that the API layer could have access to all cell instance info. That approach was discarded in favor of doing cross-cell DB queries. Another priority was the addition of alternate build candidates being sent to the cell, so that after a request to build an instance is scheduled to a cell, the local cell conductor can retry a failed build without having to go back through the entire scheduling process. I’ve already got some code for doing this, and will be working on it in the coming weeks.
In the afternoon we discussed Placement. One of the problems we uncovered late in the Pike cycle was that the Placement model we created didn’t properly handle migrations, as migrations involve resources from two separate hosts being “in use” at the same time for a single instance. While we got some quick fixes in Pike, we want to implement a better solution early in Queens. The plan is to add a migration UUID, and make that the consumer of the resources on the target provider. This will greatly simplify the accounting necessary to handle resources during migrations.
We moved on to discuss the status of Traits. Traits are the qualitative part of resources, and we have continued to make progress in being able to select resource providers who have particular traits. There is also work being done to have the virt drivers report traits on things such as CPUs.
We moved on to the biggest subject in Placement: nested resource providers. Implementing this will enable us to model resources such as PCI devices that have a number of Physical Functions (PFs), each of which can supply a number of Virtual Functions (VFs). That much is easy enough to understand, but when you start linking particular VCPUs to particular NUMA nodes, it gets messy very quickly. So while we outlined several of these complex relationships during the session, we all agreed that completing all that was not realistic for Queens. We do want to keep those complex cases in mind, though, so that anything we do in Queens won’t have to be un-done in Rocky.
We briefly touched on the question of when we would separate Placement out into its own service. This has been the plan from the beginning, and once again we decided to punt this to a future cycle. That’s too bad, as keeping it as part of Nova is beginning to blur the boundaries of things a bit. But it’s not super-critical, so…
We then moved on to discuss Ironic, and the discussion centered mainly on the changes in how an Ironic node is represented in Placement. To recap, we used to use a hack that pretended that an Ironic node, which must be consumed as a single unit, was a type of VM, so that the existing paradigm of selection based on CPU/RAM/disk would work. So in Ocata we started allowing operators to configure a node’s resource_class attribute; all nodes having the same physical hardware would be the same class, and there would always be an inventory of 1 for each node. Flavors were modified in Pike to accept an Ironic custom resource class or the old VM-ish method of selection, but in Queens, Ironic nodes will only be selected based on this class. This has been a request from operators of large Ironic deployments for some time, and we’re close to realizing this goal. But, of course, not everyone is happy about this. There are some operators who want to be able to select nodes based on “fuzzy” criteria, like they were able to in the “old days”. Their use cases were put forth, but they weren’t considered compelling enough. You can’t just consume 2 GPUs on a 4-GPU node: you must consume them all. There may be ways to accomplish what these operators want using traits, but in order to determine that, they will have to detail their use cases much more completely.
Thursday began with a Nova-Cinder discussion, which I confess I did not pay a lot of attention to, except for the parts about evolving and maintaining the API between the two. The afternoon was focused on Nova-Neutron, with a lot of discussion about improving the interaction between the two services during instance migration. There was some discussion about bandwidth-based scheduling, but as this depends on Placement getting nested resource providers done, it was agreed that we would hold off on that for now.
We wrapped up Thursday with another deep-dive into Placement; this time focusing on Generic Device Management, which has as its goal to be able to model all devices, not just PCI devices, as being attached to instances. This would involve the virt driver being able to report all such devices to the placement service in such as way as to correctly model any sort of nested relationships, and determine the inventory for each such item. Things began to get pretty specific, from the “I need a GPU” to “I need a particular GPU on a particular host”, which, in my opinion, is a cloud anti-pattern. One thing that stuck out for me was the request to be able to ask for multiple things of the same class, but each having a different trait. While this is certainly possible, it wasn’t one of the use cases considered when creating the queries that make placement work, and will require some more thought. There was much more discussed, and I think I wasn’t the only one whose brain was hurting afterwards. If you’re interested, you can read the notes from the session.
Friday was reserved for all the things that didn’t fit into one of the big topics covered on Wednesday or Thursday. You can see the variety of things covered on this etherpad, starting around line 189. We actually managed to get through the majority of those, as most people were able to stay for the last day of PTG. I’m not going to summarize them here, as that would make this post interminably long, but it was satisfying to accomplish as much as we did.
After the conference, my wife joined me, and we spent the weekend out in the nearby Rockies. We visited Rocky Mountain National Park, and to describe the views as breathtaking would be an understatement.
View of the mountains in Rocky Mountain National Park.
I would certainly say that the week was a success! It took me a few days upon returning to decompress after a week of intense meetings, but I think we laid the groundwork for a productive Queens release!
Two days ago I underwent Lasik surgery to correct my nearsightedness. It went as well as could be expected, and I’m currently seeing 20/20 without glasses or contacts. There is a little bit of hazy ghosting around bright objects, but that’s supposed to go away as my corneas heal.
First, the place where I had it done, LasikPlus, is first-class in every respect. They understand customer experience, and do everything to make the experience, including coughing up around $4K, as pleasant as it can possibly be. And my doctor, Bruce January, M.D., had a positive energy that was so infectious that it inspired confidence. The staff also did a great job explaining just what will happen, including trying to explain what it will feel like. The thing is, that only goes so far. So here are my impressions.
The first step in the process is cutting a flap in your cornea’s surface to expose the main part of the lens. There are two separate machines involved, so they have you lay down on a small (comfortable!) table that pivots between two machines. The first machine is where they place a circular device on the eye to hold it still.
I’m getting ready for the first part of the procedure to start.
Before this is done, some numbing drops are placed in your eyes, so there is no pain. You are told that you will feel it pressing on your eyeball, and that while there won’t be any pain, it will feel a little weird. That’s an understatement! After the device is on your eye, they move you a few feet to the second machine, which does the actual cutting of the cornea using a femtosecond laser. This is where it gets trippy.
You’re staring up and see several very bright white lights, but of course, you can’t blink. When they have you lined up, the machine presses down hard on the aforementioned circular device, and sure, it feel strange having that much pressure on your eyeball. But is even stranger is that you go blind in that eye! From bright white lights to black in a split second! Then you start seeing all sorts of colored patterns moving around. If you ever pressed against your closed eyes when you were a kid and saw the resulting visual effects, it’s sort of like that, but 100 times more intense. I saw spots of different colors that moved around randomly, leaving a trail of dots behind them. And while the visual show was interesting, the whole eyeball pressure thing was getting more and more uncomfortable. I’m not sure of the elapsed time; it was probably less than 30 seconds. But it felt a lot longer! When it was done, the pressure released, and the white lights reappeared. Now it was time to be wheeled back to the first machine, and repeat for the second eye. This time I had a much better idea as to what to expect, and while it was equally uncomfortable, it seemed to go more quickly.
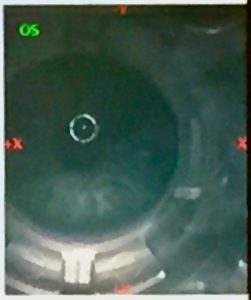
This was the view on the monitor as I was about to have the flap cut into my cornea
Now it was time to get up and walk to the machine that actually reshaped the lenses. It was odd – I could sort of see where I was going, but felt quite a bit disoriented after the previous procedure. The operating room assistant guided me over, and I laid down for part two.
This time there was no discomfort; nothing pressing on the eye, just a small device to keep you from blinking. They told you to just keep focused on the green dot in the middle, while the red lights around it danced and blinked. After a few seconds of blinking it sounded like someone turned on a vacuum cleaner, and the red lights got more intense. The green dot turned into a green patch as the laser etched the lens. Then there’s the smell – you’ve smelled burning hair, right? Well, it’s pretty close to that. I don’t know why I was surprised, since I knew that the whole point of this procedure was to have a laser burn away parts of your lens to re-shape it, but smelling it brought home the reality of what was going on.
The whole process lasted only a few seconds. The smell went away, the vacuum sound stopped, and the green light returned to a dot. Then I saw what looked like a small brush going across my eye. This was the surgeon replacing the corneal flap over my eye. My wife was watching this on the monitors and said it looked like the doctor was smoothing wallpaper. Oh, I didn’t mention that the whole procedure area is viewable from the waiting area, including monitors that show what the doctor is seeing. Just one more thing that showed that they put a lot of thought into the whole experience. The photos here were all taken by my wife Linda while I was undergoing the procedure.
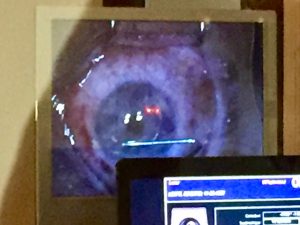
The view on the monitor during the second half of the procedure
Repeat with the other eye, and done! When I got up, I could see clearly enough, although everything had a fuzziness to it. Off to the side room where they give your eyes a quick once-over, repeat the instructions to you for applying the various drops, and we’re done!
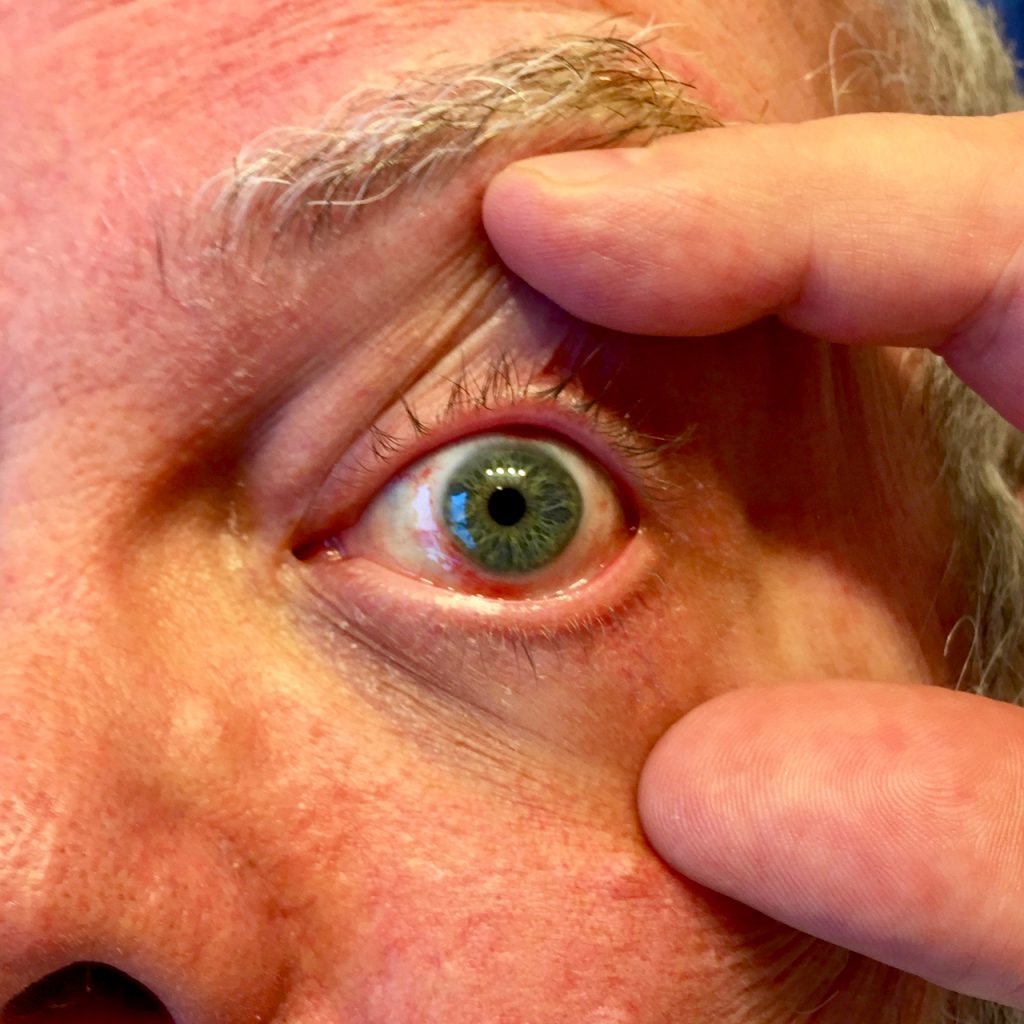
Wearing the protective goggles over my very bloodshot eyes 10 minutes after the procedure
I put on the sunglasses they give you, and got in the car for the ride home. Even with sunglasses and my eyes closed, it was uncomfortably bright outside. I kept my eyes closed for the whole ride home, only opening when we arrived. By now the numbing drops were beginning to wear off, and my eyes were watering like crazy. They were also beginning to burn a bit, and soon reminded me of the time I was cutting jalapeño peppers and absent-mindedly rubbed my eyes! Every so often my eyes would get uncomfortable and I’d open them a bit, only to have tears come gushing down my cheeks! It was clear that my eyes were not very happy! I did end up going through a lot of tissues that day!
They advise you to keep your eyes closed for several hours, and recommend that you take a nap. They give you some Tylenol PM to help you sleep, but that didn’t do anything at all for me. I have some over-the-counter sleep aid pills that I use when flying overseas, so I took a couple of those, and slept for the next 5 hours. When I awoke, my eyes felt better, although still a bit scratchy. I kept the drops up, and tried to keep my eyes closed as much as possible.
The next morning I awoke to much clearer vision. Bright areas had a soft halo around them, but that’s to be expected as the cornea heals. I kept up with the drops, as my eyes would start to feel a bit scratchy if I went too long without them. I had my day-after exam, and all was fine.
Some bruising is visible the day after surgery
So 24 hours after having my eyes zapped by lasers I was able to return to working, which requires staring at a screen. The trick is to limit it to 20 minutes at a time, after which I put in more eyedrops and get up to walk around and let my eyes focus on other things for a few minutes. And yes, this post was written in small chunks to give my eyes some rest.
Some post-Lasik thoughts:
As is common with people my age, I need reading glasses. Before the surgery, when I was wearing my contacts and needed to see something up close, the readers were necessary. However, when I removed my contacts I could see perfectly well up close. This was handy when I would awake in the morning and want to set an alarm on my phone for, say, 5 minutes of snoozing. Since the surgery I can’t read my phone when I pick it up in the morning! Guess I’ll have to keep a pair of readers on my nightstand.
Somewhat related to this, when I rolled over to say good morning to my wife, I couldn’t see her very clearly, either. This was far more troubling to me. I guess I had taken it for granted that I would always be able to see her when we woke up. This will take some getting used to. I’m hoping that as my eyes heal, this will not be as severe. I’m not sure the convenience of not having to wear contacts is worth losing this.