It is not my intent here to create a full tutorial on using graph databases; I just want to convey enough understanding so that you might see why they are a better fit for placement than a relational DB.
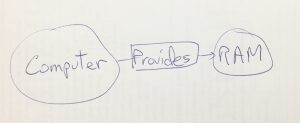
The most basic thing to understand is that your whiteboard design is your database design. Here’s what I mean by that:
This is the general form of the CREATE statement in Neo4j’s declarative language Cypher:
CREATE (obj1)-[relates_to]->(obj2)
And here is the specific code for creating that in Cypher:
CREATE (cnode:ComputeNode)-[:PROVIDES]->(mem:MEMORY_MB {
total: 10000, used: 2000})
RETURN cnode, mem
Note that the syntax is close to ASCII diagramming, using parentheses to enclose nodes, square brackets to enclose relationships, dashes to connect them, and arrows to indicate the direction of the relationship. Also note that nodes and relationships can have properties; here I gave the memory a ‘total’ of 10,000, and a ‘used’ value of 2000. These can be used to filter results to only those that have the necessary amounts. I used the Placement standard resource class ‘MEMORY_MB’ for the RAM to make it more familiar.
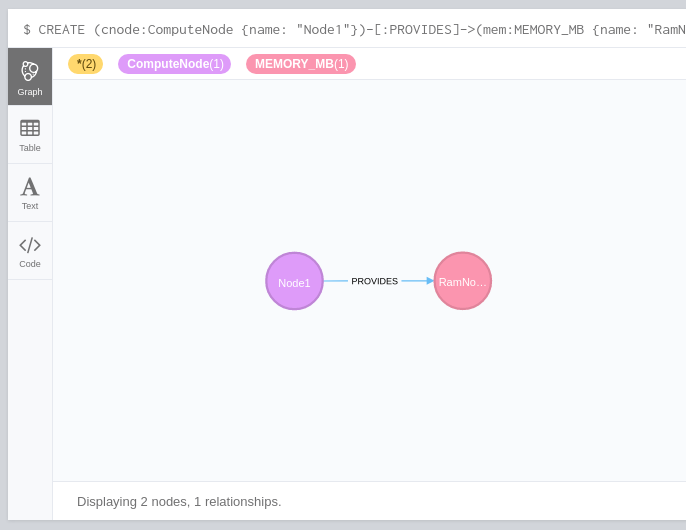
Neo4j comes with a browser that lets you visualize your data. So when I ran the above code in the browser, I get this back:
Ok, I guess at this point it seems almost toy-like. So here’s something a bit more interesting:
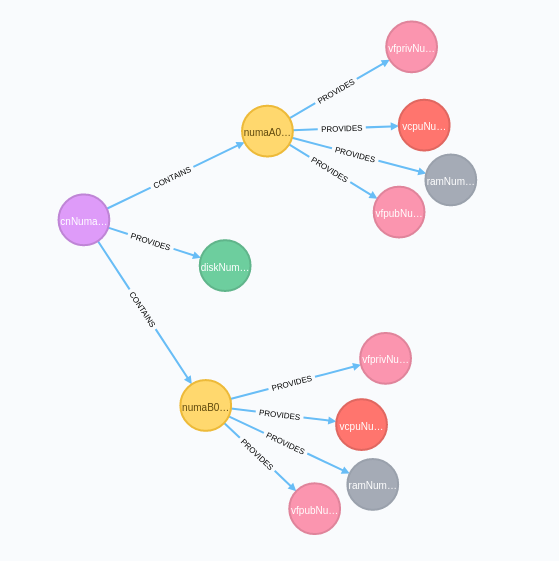
This is a compute node (purple) that provides disk (green), and contains two NUMA nodes (yellow), each of which provides VCPU (orange), RAM (grey), and VFs (pink). The model as stored in the DB matches the real world, and doesn’t require expensive JOINs to retrieve.
And finally (just to show off a little), I created 500 compute nodes and associated them with aggregates. In Nova/Placement lingo, an ‘aggregate’ is a way to associate things that have something in common. Here’s what one such model looks like:
The pink dot in the center is an aggregate, with purple compute nodes attached to it, and attached to those compute nodes are green disks, yellow memory, grey VCPU, and red VFs. And though they are faint, the lines connecting those things are the key to why this works so well: you can traverse these relationships in any direction in a single query– no joins required. I’ll give some specific examples of querying nested and shared resources in the next post in this series.
The work on the OpenStack Placement service has been getting more and more complex in the last few months, as the service has matured to handle more complex resources. At first, things were pretty basic: you had a ResourceProvider, and it had Inventory of various ResourceClasses. You told Placement how much you needed of one or more ResourceClasses, and it returned those providers that had enough to meet your request. Simple.
This was the world where the ResourceProviders were simple computers, and the resources were that computer’s RAM, disk, and VCPUs. You wanted a VM with so much RAM, disk, and VCPU, and Placement returned those compute nodes that could provide that. This was all implemented internally using common relational database techniques, and it was simple and fast.
Now we are starting to model more complex resources, and the complexity is growing rapidly. We have sharing providers, with the canonical example being a shared disk whose storage can be consumed by a number of compute nodes, so there needs to be a way to model that. There are also nested providers, such as a network virtual function (VF) that is provided by a NIC that is part of the computer. This means that when you ask Placement for an instance that has a VF, it has to know the relationship between the compute node (root provider), the NIC (resource provider), and the VF (resource), and return the whole structure. These nested relationships aren’t limited to just one level; when you add in things such as NUMA, there can be many such nesting levels.
The modeling complexity has now grown significantly, and the ability to implement this complexity using relational databases, while certainly still possible, requires solutions that are less and less readily comprehensible for anyone looking at the code for the first time. I worked as a SQL DBA for several years, so I’m not a stranger to SQL, but I need to read the code several times, usually with a pen and paper to diagram things, before I truly understand what each bit is doing. If you’d like to see what I mean, peruse the _get_trees_matching_all() method of nova/api/openstack/placement/objects/resource_provider.py. It’s truly amazing that that code works as well as it does, but drives home the point that overly complex solutions indicate that there is a poor fit between your model and the thing that you’re trying to model.
No database will ever get rid of the complexity, of course, but some are much better suited to handling relations of these types than traditional relational databases. At the last PTG, these discussions, as well as the drawings that were made to illustrate the relationships, made me think about another type of database: graph databases. So I started playing around with the most popular one, Neo4j. Graph databases use a relationship-first approach to storing and accessing data, and this seemed to better model the needs of Placement than an RDBMS.
I do realize that it is too late for OpenStack Placement to change something as fundamental as their data storage model. But after playing around with Neo4j for a little while, it’s obvious that it fits the problem domain better than MySQL does. I’ll demonstrate this in the next post in this series. But the current state of Placement reminds me of the old saying “when all you have is a hammer…”.
We recently held the OpenStack PTG for the Rocky cycle. The PTG ran from Monday to Friday, February 26 – March 2, in Dublin, Ireland. So of course the big stuff to write about would be the interesting meetings between the teams, and the discussions about future development, right? Wrong! The big news from the PTG: Snow! So much so that Jonathan Bryce created the hashtag #SnowpenStack to commemorate the event!
Yes, Ireland was gripped by a record cold snap and about 5 inches/12 cm. of snow. Sure, I know that those of you who live in places where everyone owns a snow shovel just read that and snickered, but if you don’t have the equipment and experience to deal with it, it is a very big deal. They were also forecasting over twice that, and seeing how hard it was for them to deal with what they got, I’m glad it was only that much.
The warnings posted ahead of the big storm
Since the storm was considered an emergency situation, and people were told to go home and stay there, that meant that there was no staff available for the conference, and it had to be shut down early. The people who ran the venue, Croke Park, Ireland’s biggest sports stadium, were wonderful and did everything they could to accommodate us.
Wait, what? A tech conference in a stadium? Turns out they also have conference facilities on the upper floors of the stadium, so it wasn’t so odd after all. There is a hotel across the street from the entrance to the stadium, but it was completely booked on the Friday/Saturday I would be arriving, due to an important Rugby match between Ireland and Wales at Croke Park on Saturday. So I ended up at a hotel about a mile walk from the stadium. Which was fine at first, but turned out to be a bit of a problem once it got cold and the snows came, as it made the walk to Croke Park fairly difficult. But enough about snow – on to the PTG!
On Monday the API-SIG had a room for a full day’s discussion. However, it was remotely located at one end of the stadium, and for a while it was just the cores who showed up. We were afraid that we would end up only talking amongst ourselves, but fortunately people began showing up shortly thereafter, and by the afternoon we had a pretty good crowd.
Probably the most contentious issue we discussed was how to create guidelines for “action” APIs. These are the API calls that are made to make something happen, such as rebooting a server. We already recommend using the RESTful approach, which is to POST to the resource, with the desired action in the body of the request. However, many people resist doing that for various reasons, and decry the recommended approach as being too “purist” for their tastes. As one of the goals for the API-SIG is to make OpenStack APIs more consistent, we decided to take a two-pronged approach: recommend the RESTful approach for all new APIs, and a more RPC-like approach for existing APIs. We will survey the OpenStack codebase to get some numbers as to the different ways this is being done now, and if there is an approach that is more common than others, we will recommend that existing APIs use that format.
We also discussed the version discovery documents that have been stalled in review for some time. The problem with them is that they are incredibly detailed, making your brain explode before you can get all the way through. I volunteered to write a quick summary document that will be easier for most people to digest, and have it link to the more detailed parts of the full document.
Tuesday was another cross-project day. I started the day checking out the Kubernetes SIG, and was very impressed at the amount of interest. The room was packed, and after a round of introductions, they started to divide up what they planned to work on that day. Since I had other sessions to go to, I left before the work started, and moved to the room for the Cyborg project. This project aims to provide management of various acceleration resources, such as FPGAs, GPUs, and the like. I have an interest in this both because of my work with the Placement service, and also because my employer sells hardware with these sorts of accelerators, and would like to have a good solution in place. The Cyborg folks had some questions about how things would be handled in Placement, and I did my best to answer them. However, I wasn’t sure how much the rest of the Nova team would want to alter the existing VM creation flow to accommodate Cyborg, so we brainstormed for a while and came up with an approach that involved the Cyborg agent monitoring notifications from Nova to detect when it needed to act. This would mean a lot more work for Cyborg, and would sometimes mean that a new VM that requested an accelerator may not have the accelerator available right away, but it had the advantage of not altering Nova. So imagine our surprise when the Nova-Cyborg joint meeting later that day rolled around, and the Nova cores were open to the idea of adding a blocking call in the build process to call out to Cyborg to do whatever preparation would be necessary to have the accelerator ready to go, so that when the VM is ready, any accelerators would also be ready to be used. I’m planning on staying in touch with the Cyborg team to help them however I can make this work.
On to Wednesday, not only did the Nova discussions begin, but the snow began to fall in Dublin.
Dublin morning – the first snowfall of #SnowpenStack
As is the custom, we prepared an etherpad ahead of time with the various topics to discuss, and then organized it into a schedule so that we don’t rabbit-hole too deeply on any topic. If you look over that etherpad, you’ll see quite a bit of material to discuss. It would be silly for me to reproduce those topics and their conclusions here; instead, if you have an interest in Nova, reviewing that etherpad is the best way to get an understanding of what was decided (and what was not!).
The day’s discussions started off with Cells V2. Some of the more interesting topics were what to do when a cell goes down. For example, Nova should still be able to list all of a user’s instances even when a cell is down; they just won’t be able to interact with that instance through Nova. Another concern was more internal: are we going to remove the (few) upcalls from a cell to the outer-level API? While it has always been a design tenet that a cell cannot call the API-level services, it has been necessary in a few cases to bend that rule.
The view from the area where lunch was served.
The afternoon was scheduled for Placement discussions, and there sure were enough of ’em! So much material to cover that it merited its own etherpad! And it’s a good thing we have an etherpad to record this stuff, because I’m writing this nearly two weeks after the fact, and I’ve already forgotten some of the things we discussed! So if you’re interested in any of the Placement discussions, that etherpad is probably your best source for information.
Thursday started off with the Nova-Cinder discussion. Now that multi-attach is a reality, we could finally focus on many of the other issues that have pushed to the background for a while. Again, for any particular topic, please refer to the Nova etherpad.
After that it was time for our team photo. We weren’t allowed onto the pitch at Croke Park, so the plan was to line up on the perimeter of the pitch to have the picture taken with the stadium in the background. But remember I mentioned that cold snap? Well, it was in full force, and we all bundled up to go outside for the photo.
You think it was cold? 🙂 We had more discussions planned for the afternoon and Thursday, but by then we got word that they needed to have us all out of the stadium by 2pm so that they could send their workers home. The plan was to have people go back to their hotel, and the PTG would more or less continue with makeshift meeting areas in the hotel across the street from the stadium, where most attendees were staying. But since my hotel was further away, I headed back there and missed the rest of the events. All public transportation in Dublin had shut down!
All public transportation in Dublin was shut down for several days.
That also meant that Dublin Airport was shut down, canceling dozens of flights, including ours. We ended up having to stay in the hotel an extra 2 nights, and our hotel, the Maldron Parnell Square, was very accommodating. They kept their restaurant open, and some of the workers there told me that they couldn’t get home, so the hotel offered to put them up so that they could keep things running.
By Saturday things had cleared up enough that pretty much everything was open, and we rebooked our flight to leave Sunday. That left just enough time to enjoy a little more of what Dublin does best!
Drinking a pint of Guinness, wearing my Irish wool sweater and Irish wool cap!
There was some discussion among the members of the OpenStack Board as to whether continuing to hold PTGs is a good idea. The main reason not to have them, in my opinion, is money. Without the flashy corporate sponsorships and expensive admission prices of the Summits, PTGs cost money to put on. It certainly isn’t because the PTG fails to meet its objective of bringing together the various development and deployment teams to make OpenStack better. Fortunately, the decision was to hold at least one more PTG, with the location still to be determined. Maybe by then enough people will realize that without a strong development process, all the fancy Summits in the world won’t make OpenStack better, and the PTGs are a critical part of that development process.
The ‘cloud’ in cloud computing derives from the amorphous location of your resources. Sure, you have a virtual server, but all you really know is that it’s somewhere on your cloud provider’s hardware, and you can reach it at a certain IP address. You generally don’t care about its exact location.
There are times, though, when you might care. High Availability (HA) designs are a good example of this: you want to avoid putting all your eggs in one basket, so to speak. You don’t want your resources in the same failure domain, so that when there is an outage, it is likely to only affect one part of that provider’s cloud, while other parts remain functional. In these cases, you would want to request that your VMs are placed in different locations so that in the event of an outage in one part of the cloud, the rest should remain functional.
After many discussions about this recently in the #openstack-nova IRC channel, I’ve thought about how to approach this, and wanted to write down my ideas so that others can comment on them.
The placement service already has the concept of aggregates, which are used primarily for determining which resources can be shared with other resources. I think that we can use aggregates for affinity modeling, too. Note: Placement aggregates are not Nova aggregates!
A resource’s location can be described at many levels. In the example of a VM, it is located on a host machine. This machine is located in a rack of machines. These racks are located in rows. Rows are located in rooms. Rooms are located… well, you get the idea. These more or less correspond with sharing the same network segments, power sources, etc. The higher you go up this nesting, the more isolated things are from each other.
As an operator of a cloud, you define which of these groupings you want to give your users the ability to choose from. You could, of course, choose to expose every possible layer to your users, but that may not be practical (or necessary). So for this example, let’s assume that users can specify affinity or anti-affinity at the rack, row, and room levels. Here’s how I think this can be achieved in placement:
Define an aggregate for each rack, and then add all the host machines in that rack to that agg. Once that’s done, it’s a simple matter to determine if a potential candidate for a new VM is in the same rack or not by simply testing membership in that aggregate.
Next, define an aggregate for the row. Add all the hosts in that row to this row aggregate. Yeah, that sounds cumbersome, but really, we could create a simple tool that lets the operator select the racks for a row, and iteratively adds the hosts in those racks to that aggregate. Once again, when this is done, it is simple to determine if a candidate is in a given rack by simply checking if it is a member of that rack’s aggregate. The same pattern would hold for defining the room aggregate.
While this would indeed require some setup effort by operators, I don’t think it’s any worse than other proposals. These definitions would be relatively static, as the layout of a DC doesn’t change too often, so the pain would be mostly up front, with the occasional update necessary.
Now we start to handle requests like “give me an instance that has this much RAM, VCPU, and disk, but make sure it’s in a different row than instance X”. To do this, we just need to look up what row aggregate instance X is in, and filter out those hosts that are also in that same aggregate. The naming of these grouping levels would be left to the operator, so they could be in control of how granular they want this to be, and also make sure that their flavors match these names.
This idea doesn’t address the “soft affinity” issue, which basically says “give me an instance in Row R, but if there isn’t any candidate found there, give me one in the closest row to that”. The notion of “closest”, or any sort of “distance”, for that matter, isn’t really something that is clearly defined, as it could be physical location, or number of network switches, or pretty much anything else. But if it is determined to be a priority to support, perhaps we could add a column to contain some sort of distance/location identifier to the PlacementAggregate table. Or maybe we could think up some other way of defining relative location. In any case, I think it would be a poor choice to design an entire system around a relatively esoteric requirement. We need support for robust affinity/anti-affinity in Placement, and I think we can get this done without adding more tables, relationships, and complexity.
One of the changes coming in the Queens release of OpenStack is the addition of alternate hosts to the response from the Scheduler’s select_destinations() method. If the previous sentence was gibberish to you, you can probably skip the rest of this post.
In order to understand why this change was made, we need to understand the old way of doing things (before Cells v2). Cells were an optional configuration back then, and if you did use them, cells could communicate with each other. There were many problems with the cells design, so a few years ago, work was started on a cleaner approach, dubbed Cells v2. With Cells v2, an OpenStack deployment consists of a top-level API layer, and one or more cells below it. I’m not going to get into the details here, but if you want to know more about it, read this document about Cells v2 layout. The one thing that’s important to take away from this is that once a process is cast to a cell, that cell cannot call back up to the API layer.
Why is that important? Well, let’s take the most common case for the scheduler in the past: retrying a failed VM build. The process then was that Nova API would receive a request to build a VM with particular amounts of RAM, disk, etc. The conductor service would call the scheduler’s select_destinations() method, which would filter the entire list of physical hosts to find only those with enough resources to satisfy the request, and then run the qualified hosts through a series of weighers in order to determine the “best” host to fulfill the request, and return that single host. The conductor would then cast a message to that host, telling it to build a VM matching the request, and that would be that. Except when it failed.
Why would it fail? Well, for one thing, the Nova API could receive several simultaneous requests for the same size VM, and when that happened, it was likely that the same host would be returned for different requests. That was because the “claim” for the host’s resources didn’t happen until the host started the build process. The first request would succeed, but the second may not, as the host may not have had enough room for both. When such a race for resources happened, the compute would call back to the conductor and ask it to retry the build for the request that it couldn’t accomodate. The conductor would call the scheduler’s select_destinations() again, but this time would tell it to exclude the failed host. Generally, the retry would succeed, but it could also run into a similar race condition, which would require another retry.
However, with cells no longer able to call up to the API layer, this retry pattern is not possible. Fortunately, in the Pike release we changed where the claim for resources happens so that the FilterScheduler now uses the Placement service to do the claiming. In the race condition described above, the first attempt to claim the resources in Placement would succeed, but the second request would fail. At that point, though, the scheduler has a list of qualified hosts, so it would just move down to the next host on the list and try claiming the resources on that host. Only when the claim is successful would the scheduler return that host. This eliminated the biggest cause for failed builds, so cells wouldn’t need to retry nearly as often as in the past.
Except that not every OpenStack deployment uses the Placement service and the FilterScheduler. So those deployments would not benefit from the claiming in the scheduler change. And sometimes builds fail for reasons other than insufficient resources: the network could be flaky, or some other glitch happens in the process. So in all these cases, retrying a failed build would not be possible. When a build fails, all that can be done is to put the requested instance into an ERROR state, and then someone must notice this and manually re-submit the build request. Not exactly an operator’s dream!
This is the problem that alternate hosts addresses. The API for select_destinations() has been changed so that instead of returning a single destination host for an instance, it will return a list of potential destination hosts, consisting of the chosen host, along with zero or more alternates from the same cell as the chosen host. The number of alternates is controlled by a configuration option (CONF.scheduler.max_attempts), so operators can optimize that if necessary. So now the API-level conductor will get this list, pop the first host off, and then cast the build request, along with the remaining alternates, to the chosen host. If the build succeeds, great — we’re done. But now, if the build fails, the compute can notify the cell-level conductor that it needs to retry the build, and passes it the list of alternate hosts.
The cell-level conductor then removes any allocated resources against the failed host, since that VM didn’t get built. It then pops the first host off the list of alternates, and attempts to claim the resources needed for the VM on that host. Remember, some other request may have already consumed that host’s resources, so this has a non-zero chance of failing. If it does, the cell conductor tries the next host in the list until the resource claim succeeds. It then casts the build request to that host, and the cycle repeats until one of two things happen: the build succeeds, or the list of alternate hosts is exhausted. Generally failures should now be a rare occurrence, but if an operator finds that they happen too often, they can increase the number of alternate hosts returned, which should reduce that rate of failure even further.