So this week was the big post-op appointment with my surgeon following my total knee replacement. Six weeks: that was the first big milestone, where my progress would be assessed to make sure that I was recovering well. It was also the point where some of the more annoying things that I had to do would end (assuming I had progressed well): no more compression stocking; no more sleeping only on my back with my foot in a foam block to stretch the knee, and no more walker. Full disclosure: I hadn’t used the walker at all since about 2 weeks after the surgery, but the doctors insisted on it as a safety measure, so… 😉
I wasn’t too concerned about the exam, as I had been doing the physical therapy religiously all this time, and had a gotten a good deal of flexibility and strength back. And that’s exactly how the exam went: I was given a proverbial gold star, moving me ahead to the next phase. Joy!
One thing that has always concerned me was my use of pain medication. After surgery they start you on Hydrocodone, a strong opiod painkiller, and boy, did I need it! But as I healed the severe pain diminished, and I really only needed it when doing some of the more painful PT exercises. So two weeks later they switched me to Tramadol, a non-opiod pain medication. Since it’s not an opiod, it is supposedly not as addictive, nor as difficult to stop using once you no longer need it.
So, given my progress on the healing front, and my missing being able to share a glass of wine with my wife at dinner, I decided to stop taking the medication. Sure, it would be uncomfortable for a day or two, but after that I’ll be clean!
So my last dose was this past Tuesday at 11am. Wednesday morning I awoke with what appeared to be a cold: runny nose, congestion, watery eyes, sneezing, and a dry, hacking cough. Oh, great – now I have to deal with a cold on top of everything else!
Towards the end of the afternoon, I started to feel lethargic. OK, I thought, this is the drug withdrawal, and I have to tough it out. I was also feeling chilled, but I didn’t know if that was the cold or the withdrawal causing that. My wife took good care of me, and made a delicious ramen to warm me up, with lots of chili to clear my sinuses, and lots of kale and other veggies to keep me strong.
I went to bed, trying to relax enough to fall asleep, but I just couldn’t get comfortable. I had taken some Tylenol to help ease any knee pain, but my knee wasn’t really bothering me that much. No matter how I tried to position myself, I could feel the muscles in my legs twitching, making it impossible to lay still. I didn’t want my constant movement to keep my wife awake, so I got up. Maybe walking around a bit would calm my legs down, so I walked around the house for a while. That helped a little, but I still didn’t feel like I could rest, so I sat down at the computer, and figured I’d see if there were any tips I could find on dealing with Tramadol withdrawal.
Well, it wasn’t hard to find that information! And man was there a ton of it! The first page I read was a message board where different people described their experiences, and it was like a slap in my face! They described everything I had been feeling; even my “cold” wasn’t a cold, but just some of the symptoms of withdrawal!
I continued reading a variety of sites, and it reinforced all of the anecdotal reports of the first site I read. What was worse, though, is the timeline they described for these symptoms: they would peak after 72 hours without the medication, and continue for 10 days or so! I was barely 36 hours into my withdrawal, and I wasn’t going to be able to handle this without locking myself in a padded room for the duration. Every single site recommended the only way to stop is to gradually wean yourself by slowly reducing your dosage, so that’s what I decided to do. I felt defeated: I had been kicking ass on this whole knee-replacement thing since the beginning, and now I finally ran into something that kicked mine. So I reluctantly took a Tramadol pill at 11:30pm, and an hour or so later I was feeling better enough to attempt sleeping. I did manage to get a few hours, so this morning I’m a little sore and grouchy. My (revised) plan is to go with taking it at 12 hour intervals for a few days, then increase it to 16 hour intervals for another few days, and adjust that as needed until I’m off it completely. No heroic cold turkey for me anymore!
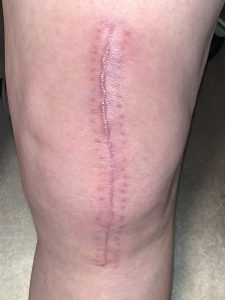
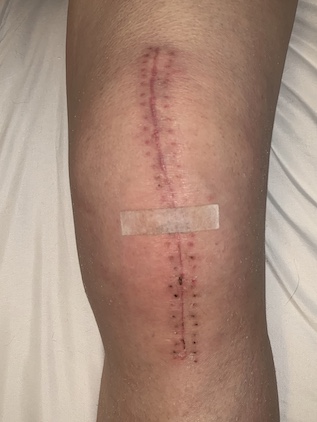
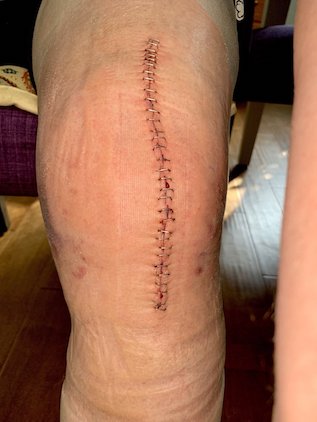
Let me close with a current photo of how my knee is progressing. The swelling continues to diminish, but it’s still there. The scar is looking fine, thanks to the Vitamin E oil I rub in it daily.