
![]()
Last week was the first-ever OpenStack PTG (Project Teams Gathering), held in Atlanta, Georgia. Let’s start with the obvious: the name is terrible, which made it very hard to explain to people (read: management at your job) what it was supposed to be, and why it was important. “The Summit” and “The Midcycle” were both much better in that regard. Yes, there was plenty of material available on the website, but a catchier name would have helped.
But with that said, it was probably one of the most productive weeks I’ve had as a OpenStack developer. In previous gatherings there were always things that were in the way. The Summits were too “noisy”, with all the distractions of keynotes, marketplace, presentations, and business /marketing people all over the place. The midcycles were much more focused on developer issues, but since they were usually single-team events, that meant very little cross-project interaction. The PTG represented the best of both without their downsides. While I always enjoyed Summits, there was a bunch of stuff always going on that distracted from being able to focus on our work.
The first two days were devoted to cross-project matters, and the API Working Group sure fits that description, as our goal is to help all OpenStack projects develop clean, consistent APIs. So as a core member of the API-WG, I was prepared to spend most of my time in these discussions. However, on Monday morning our room was fairly empty, although this was probably due to the fact that we weren’t scheduled a room until the night before, so not many people knew about it. So we all pecked at our laptops for an hour or so, and then I just figured we’d start. The topic was the changes to the API stability guidelines to define what the assert:supports-api-compatibility tag a project could aim for. I outlined the basic points, and Chris Dent filled in some more details. I was afraid that it might end up being Chris and I doing most of the talking, but people started adding their own points of view on the matter. Before long the room became more crowded; I think the lively discussion attracted people (well, that and the sign that Chris added in the hallway!).
The gist of the discussion was just how strict we needed to be about when changing some aspect of a public API required a version change. Most of the people in the room that morning were of the opinion that while removing an API or changing the behavior of a call would certainly require a change, non-destructive changes like adding a new API call, or adding an additional field to a response, should be fine without a version change, since they shouldn’t break anything. I tried to make the argument for interop API stability, but I was outnumbered 🙂 Fortunately, I ran into the biggest (and loudest! 🙂 proponent for that, Monty Taylor, at lunch, and convinced him to come to the afternoon session and make his point of view heard clearly. And he did exactly that! By the end of the afternoon, we were all in agreement that any change to any API call requires a version increase, and so we will update the guidelines to reflect that.
Tuesday was another cross-project day, with discussions on hierachical quotas taking up a lot of the morning, followed by a Nova-Neutron session and another session with the Cinder folks on multi-attach. What was consistent across these sessions was a genuine desire to get things working better, without any of the finger-pointing that could certainly arise when two teams get together to figure out why things aren’t as smooth as they should be.
Wednesday began the team-specific sessions. Nova was given a huge, cavernous ballroom. It had a really bad echo, as well as constant fan noise from the air system, and so for someone like me with hearing loss, it was nearly impossible to hear anything. Wish I had worked on my lip reading!

We quickly decided to re-arrange the tables into a much more compact structure, which made it slightly better for discussions.

We had a full agenda, with topics such as cells V2, quotas, and the placement engine/API pretty much taking up Wednesday and Thursday. And like the cross-project days, it felt like we made solid progress. Anyone who had their doubts about this new format were convinced by now that the PTG was a big improvement! The discussions about Placement were especially helpful for me, because we went into the details of the complex nesting possibilities of NUMA cells and SR-IOV devices, and what the best way (if any) to effectively model them would be.
There was one dark spot on the event: my laptop died a horrible death! Thursday morning I opened the lid that I had closed a few hours earlier after an evening of email answering and Netflix watching, only to be greeted with this:
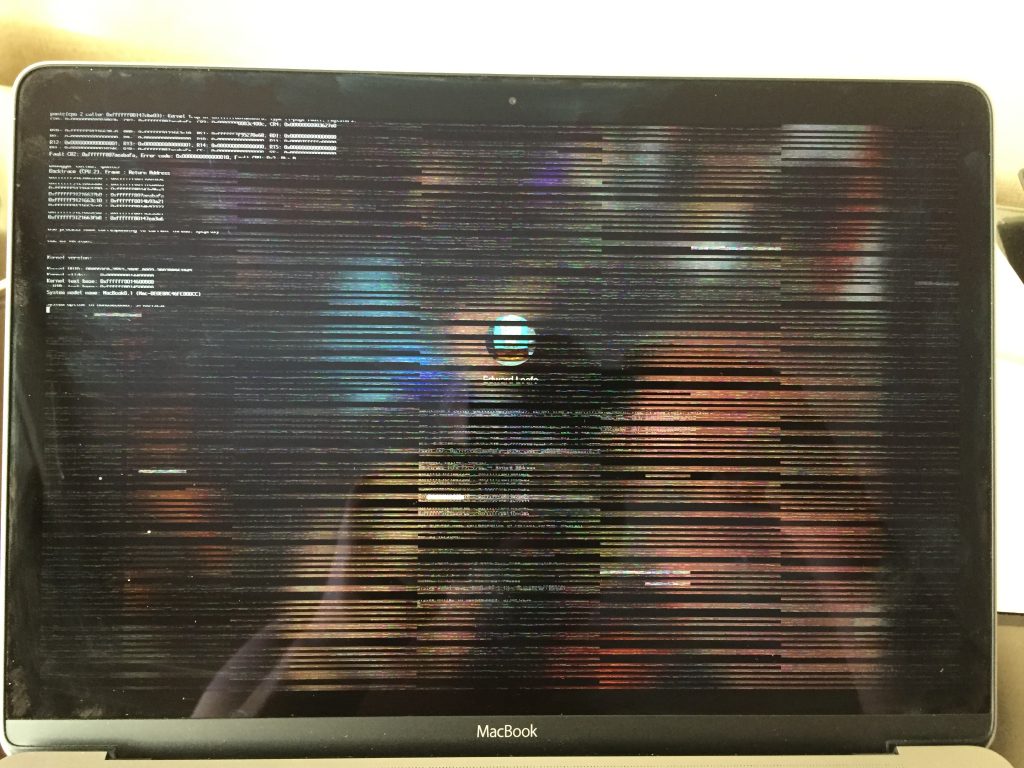
It had made a crackling sound as the screen displayed kernel panic output, so I unplugged the charger and closed the lid. After waiting several anxious minutes, I tried to turn the laptop on. Nothing. Dead. No response at all: no sound, no video… nothing. I tried again and again, using every magical keypress incantation I knew, and nothing. Time of death: 0730.
Sure, I still had my iPhone, but it’s really hard to do serious work that way. For one, etherpads simply don’t work in iOS browsers. It’s also very hard to see much of a conversation in an IRC client on such a small screen. All I could do was read email. So I spent the rest of the PTG feeling sorry for myself and my poor dead laptop. David Medberry lent me his keyboard-equipped Kindle for a while, and that was a bit better, but still, when you have a muscle-memory workflow, nothing will replace that.
The Foundation also arranged to have team photos taken during the PTG. You can see all the teams here, but I thought I’d include the Nova team photo here:

Right after the last session on Thursday was a feedback session for the OpenStack Foundation to get the attendees’ impressions of what went well, what was terrible, what should they keep doing, what should the never ever do again, and everything in between. In general, most people liked the PTG format, and felt that it was a very productive week. There were many complaints about the hotel setup (room size, noisy AC, etc.), as well as disappointment in the variety of meals and lack of snacks, but lots of praise for the continuous coffee!!
Thursday night was the Nova team dinner. We went to Ted’s Montana Grill, where we were greeted by a somewhat threatening slogan:

The staff wasn’t threatening at all, and quickly found tables for all of us. On the way through the restaurant we passed several other tables of Stackers, so I guess that this was a popular choice. We had a wonderful dinner, and on the walk home, Chet Burgess, whose parents still live in the Atlanta area, suggested we stop at the Westin hotel for a quick drink. That sounded great to me, so four of us went into the hotel. I was surprised that Chet walked right past the bar, and went to the elevators. Turns out that there is a rotating bar up on the 73rd floor! Here is the group of us going up the elevator:

It was dark in the bar area, so I couldn’t get a nice photo, but here’s a stock photo to give you an idea of what the bar looked like:

Big thanks to Chet for organizing the dinner and suggesting having drinks up in the heights of Atlanta!
Friday was a much lower-key day. Gone were the gigantic ballrooms, and down to the lower level of the hotel for the final day. Many people had left already, as many teams did not schedule 3 full days of sessions. The Nova team used the first part of the day to go over the Ocata retrospective to talk about what went well, what didn’t go so well, and how we can improve as we start working on Pike. The main points were that while communication among the developers was better, it still needed to improve. We also agreed on the need for more visual documentation of the logic flows within the code. The specs only describe the surface of the design, and many people (like myself) are visual learners, so we’ll try to get something like that done for the Placement logic so that everyone can better understand where we are and where we need to go.
I had to leave around 4pm on Friday to catch my flight home, so I headed to the ATL airport. While walking through the terminal I saw a group of men standing in one of the hallways, and recognized that one of them was Rep. John Lewis, one of the leaders of the Civil Rights movement along with Dr. Martin Luther King, Jr., whose birthplace and historic site I visited earlier in the week. I shook his hand, and thanked him for everything that he has done for this country. Immediately afterwards I texted my wife to tell her about it, and she chastised me for not getting a photo! I explained that I was too nervous to impose on him. A little while later I walked over to another part of the airport where I knew there was a restroom, since I had to empty my water bottle before going through security. When I got there, I saw some of the same group of men I had seen with Rep. Lewis earlier, but he was no longer among them. Then I looked over by the entrance to the men’s room, and I saw Rep. Lewis posing for a selfie with the janitor! I figured he wouldn’t mind taking one with me, so when he came out I apologized for bothering him again, and asked if he would mind a photo. He smiled and said it was no problem, so…

I admit that I was too excited to hold the phone very still! So a blurry photo is still better than no photo at all, right? I’ve met several famous people in my lifetime, but never one who has done as much to make the world a better place. And looking back, it was a fitting end to a week that involved the coming together of people of different nationalities, races, religions to help build a free and open software.





